Can the Modern Data Stack Handle AI Analytics?

You've been told you need a modern data stack. The proposals are coming in: Fivetran plus Snowflake plus Looker. Most companies underestimate the real cost by 5–10x once you factor in people, coordination, and the inevitable rebuilds — three to six months before anything works (or longer when the project keeps resetting). And you haven't even gotten to AI yet. When you do, the order you automate in matters more than the tools you pick.
The reason AI analytics remains out of reach for most teams isn't that the models are weak. It's that the infrastructure you've been told to build is structurally incompatible with how AI needs to operate. More than 80% of AI projects fail — twice the rate of non-AI IT projects — and the root cause isn't "bad data." It's fragmented systems that make good data impossible.
There is another path. But it requires abandoning the assumption that you need to assemble a data stack rather than adopt a platform before AI can work.
The short version: The modern data stack creates structural fragmentation that causes AI analytics to fail. Bolting AI onto existing BI tools doesn't fix the foundation — it amplifies the problems. The only architecture where AI analytics reliably works unifies ingestion, storage, a governed semantic layer, and AI into a single system. The test: can the AI only read your data, or can it also write — build models, create dashboards, modify integrations?
Assembled Stacks Are Structurally Incompatible with AI Analytics
The modern data stack assembles three to five tools: a data pipeline, a warehouse, a transformation tool, a reporting layer, maybe a semantic layer if someone remembers to add one. Each tool owns a slice of the system — different schemas, different metric definitions, different access patterns.
Here's what that looks like in practice: "revenue" means one thing in the warehouse, another in the BI tool, a third in the CFO's spreadsheet. The industry calls this semantic drift. When humans run queries, they can navigate the mess through tribal knowledge. When AI runs queries, it amplifies the inconsistency — confidently returning different answers depending on which table it hits.

The usual explanation for why AI projects fail stops at "data quality." But data quality problems are symptoms of a deeper structural issue: fragmented systems with no single source of truth. When 94% of CIOs say their data needs significant cleanup before supporting AI — and 61% admit their data simply isn't AI-ready — they're not describing a cleaning problem. They're describing an architecture problem.
And the hidden cost compounds. Every tool in the stack adds a billing relationship, an integration point, a failure mode, and an implicit hire dependency. See what your current stack actually costs → As one CEO put it after spending six weeks on Snowflake and still unable to query his own data: "This is not what I signed up for."
Bolting AI onto Your BI Tool Doesn't Fix the Foundation
Look at what passes for "AI analytics" today: Tableau with Einstein, Power BI with Copilot, ThoughtSpot with Spotter. 37% of enterprises are using AI at surface level — chatbots and copilots alongside existing workflows, minimal actual transformation.
These tools are read-only by design. The AI can query what's already there — surface anomalies, generate a chart, summarize a dashboard. But it has no authority over the system producing the data. It's a commentator, not an operator.
The result: AI on ungoverned data hallucinates confidently. Without a semantic layer that defines what "churn" or "revenue" actually means, every AI-generated insight carries an invisible asterisk — and nobody knows which version of the truth it used.
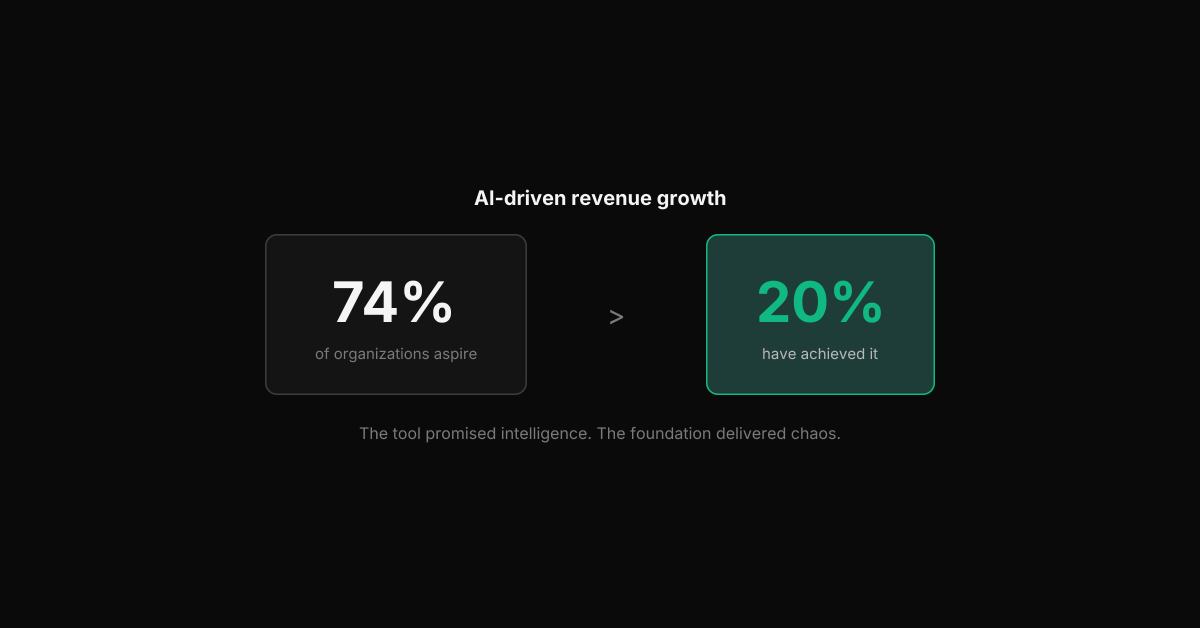
This is why early adopters are disillusioned — 74% of organizations aspire to AI-driven revenue growth, but only 20% have achieved it. The tool promised intelligence. The foundation delivered chaos.
Why Unification — Not Better Tools — Is the Prerequisite
So assembled stacks fragment the foundation, and bolt-on AI can't fix what it can't reach. The common assumption is that better tools will eventually close the gap. They won't — because the problem isn't the tools. It's the architecture. A unified data platform starts from a different premise entirely.
Here's the mechanism. In an assembled stack, when AI asks "what's our churn rate?" it has to navigate three tools with three definitions to reach an answer. In a unified platform, there's one semantic layer that defines "churn" once, and every query — whether from a dashboard, an API, or an AI agent — returns the same number. Research on enterprise SQL databases shows that adding a semantic context layer improved LLM query accuracy from 16% to 54% — and without it, accuracy on complex schemas dropped to zero.
That's not just an accuracy improvement. It's the difference between an AI that your VP of Sales can ask "what happened to pipeline this quarter?" and get a trustworthy answer — versus an AI that three people will argue with because they each got a different number.
And the timeline changes fundamentally. The three-to-six-month stack assembly isn't building analytics — it's building plumbing. A unified platform ships with the plumbing already done. You connect your sources, define your metrics once, and start asking questions. Days, not months. No separate ETL, warehouse, or BI tool to assemble →
The real shift isn't prettier dashboards — it's getting the definitions right first. When your semantic layer governs what every metric means, the dashboards become a skin. The definitions are the product. The visualizations are output.
Most "AI Analytics" Fails a Simple Test
Here's a framework for evaluating whether a platform is truly AI-native or just AI-decorated.
You demo the "AI analytics." It generates a chart. Nice. You ask it to fix the pipeline feeding the chart wrong data. It can't. You ask it to update the metric definition that three teams define differently. It can't. You ask it to build the data model the business actually needs. It can't. Demo over.
The test: can the AI only read your data, or can it also write to your system?
| Read-Only AI | Write-Access AI | |
|---|---|---|
| Queries data | Yes | Yes |
| Generates charts | Yes | Yes |
| Builds data models | No | Yes |
| Creates dashboards | No | Yes |
| Modifies integrations | No | Yes |
| Updates pipelines | No | Yes |
| Acts on insights | No — insights die in chat windows | Yes — insights become working analytics |
Most "AI analytics platforms" fail this test. Some BI tools are starting to add write capabilities within the analytics layer — ThoughtSpot's Spotter agents can build models and dashboards. But that's write access within the BI layer, not across the system. None can modify the underlying pipelines, integrations, or data sources. The distinction matters: Gartner predicts over 40% of agentic AI projects will be canceled by 2027, largely because bolting agents onto ungoverned, fragmented systems doesn't work.
The write-access future is coming. Forrester predicts 30% of enterprise app vendors will launch standard AI agent interfaces by 2026 to enable system-level interoperability. But only platforms built as unified systems from the start can deliver it — you can't bolt write access onto a stack that was never wired together.
Definite was built this way: a single system where the AI agent has read and write access across ingestion, storage, the semantic layer, and analytics — with full SQL access, open standards (DuckDB, Parquet), and no implicit data engineer hire.
Can your data actually power AI?
Enter your domain and we'll show you whether the questions your team asks can be answered by AI - or whether fragmentation is blocking it.
Try it with any company domain — no signup required.
FAQ
Do I have to build a data stack before I can use AI analytics?
No. That prerequisite is an artifact of the assembled approach — build infrastructure first, add intelligence later. A unified platform includes the infrastructure. You connect your data sources and start asking questions. The three-to-six month timeline disappears because there's nothing to assemble.
What is a semantic layer and do I need one for AI analytics?
A semantic layer defines your business metrics — revenue, churn, CAC — in one governed place. Without it, AI queries raw tables and gets different answers depending on which table it hits. It's not optional for AI analytics; it's the reason AI analytics works or hallucinates. The key is that it comes built into the platform, not as a separate project you configure.
Is there a single platform that handles ingestion, warehousing, and AI analytics together?
Yes. The category is emerging specifically because the assembled approach fails at AI. Instead of buying separate ETL, warehouse, and BI tools, you get a single system where ingestion, storage, a governed semantic layer, and AI work together from the start. The modern data stack is dead — unified platforms are what's replacing it.
How fast can I go from zero to AI-powered analytics?
With an assembled stack: three to six months before you see a working dashboard, let alone AI. With a unified platform: days. The difference isn't speed of implementation — it's that the foundation comes pre-built. There's nothing to assemble, no pipeline to wire, no separate BI tool to configure.