The Modern Data Stack is Dead. Here's What's Replacing It.

The modern data stack was supposed to be the answer. Cloud-native. Modular. Best-of-breed. Pick Snowflake for storage, Fivetran for ingestion, dbt for transformations, Looker for dashboards. Stitch them together and you've got world-class data infrastructure.
That was the promise. But something changed.
The companies that went all-in on the modern data stack are now drowning in complexity, cost, and fragmentation. And the architecture is fundamentally incompatible with AI.
The Short Version

| Modern Data Stack | AI-Native Platform | |
|---|---|---|
| Tools | 4+ (Snowflake, Fivetran, dbt, Looker) | One platform |
| Setup | Weeks to months | 30 minutes |
| Who can use it | Data engineers | Anyone |
| Cost | $100k+/year | Single subscription |
| AI-ready | No (fragmented context) | Yes (built-in semantic layer) |
For a concrete walkthrough of how Snowflake + Fivetran + dbt + Looker projects stall — timelines, vendor handoffs, and the three failure modes we see in sales calls — read You Don't Need Snowflake + Fivetran + dbt + Looker.
Why the Modern Data Stack Failed
The modern data stack emerged around 2015 when cloud data warehouses made it possible to spin up infrastructure in minutes instead of months. The philosophy: pick the best tool for each job and integrate them together. (For a concrete version of this argument from inside the Postgres ecosystem — "the regret pattern is shape, not vendor" — see Outgrown Postgres for Analytics: The Five Numbers That Tell You When.)
This worked for a while. But three problems emerged.
1. Fragmentation creates overhead.

Four tools means four vendors, four contracts, four support teams, and someone to maintain all the connections between them. That someone is usually a data engineer (or a team of them) spending time on infrastructure instead of insights.
A typical failure mode: your Fivetran sync breaks on a Saturday night because a source API changed. Your dbt models fail downstream. Your Looker dashboards show stale data. Monday morning, your exec team is looking at numbers from last week and nobody knows why. Now your data engineer is debugging across three systems instead of building anything useful.
2. Costs compound quickly.
Between compute costs, row-based pricing, per-seat licensing, and the salaries required to manage it all, startups routinely spend $100k+ per year before answering a single business question.
And the pricing models fight against democratizing data. When Looker charges per seat, you end up with five people who can access dashboards and everyone else asking them for screenshots. The tool that was supposed to make data accessible becomes a bottleneck.
3. AI can't work with fragmented data.
This is the real problem. AI needs three things to be useful for analytics: knowledge of what data exists, understanding of what the data means, and consistent definitions across the system. When your data lives in four tools with four schemas and no shared semantic layer, AI will guess. And it will often be wrong.
Ask an AI assistant "What's our churn rate?" and it has to figure out: Where is customer data stored? What defines a customer? What defines churn? Without a semantic layer answering these questions, you get a number that looks right but might be completely wrong.
Most AI analytics products today are just SQL generators. You ask a question, they write some SQL, and you get back a number that may or may not be accurate. The architecture doesn't allow for anything better. (We go deeper on why most AI data analysis tools fail and what the architecture needs to look like.)
What's Replacing It
The AI-native data stack takes a different approach: one unified platform where AI is built into the architecture from day one.
Instead of stitching together specialized tools, you get:
- One place for all your data with native connectors (no separate ETL tool)
- One semantic layer that defines what metrics mean (no conflicting definitions)
- One AI agent that understands the full context (no guessing)
That's why Definite was built this way.
How It Works
Connect your data sources. Definite has over 500 prebuilt connectors for tools like Stripe, HubSpot, Salesforce, and more. No credentials to manage across multiple systems, no pipelines to maintain.
Then ask Fi, our AI agent, anything: "What's our ARR by month? Build me a dashboard."
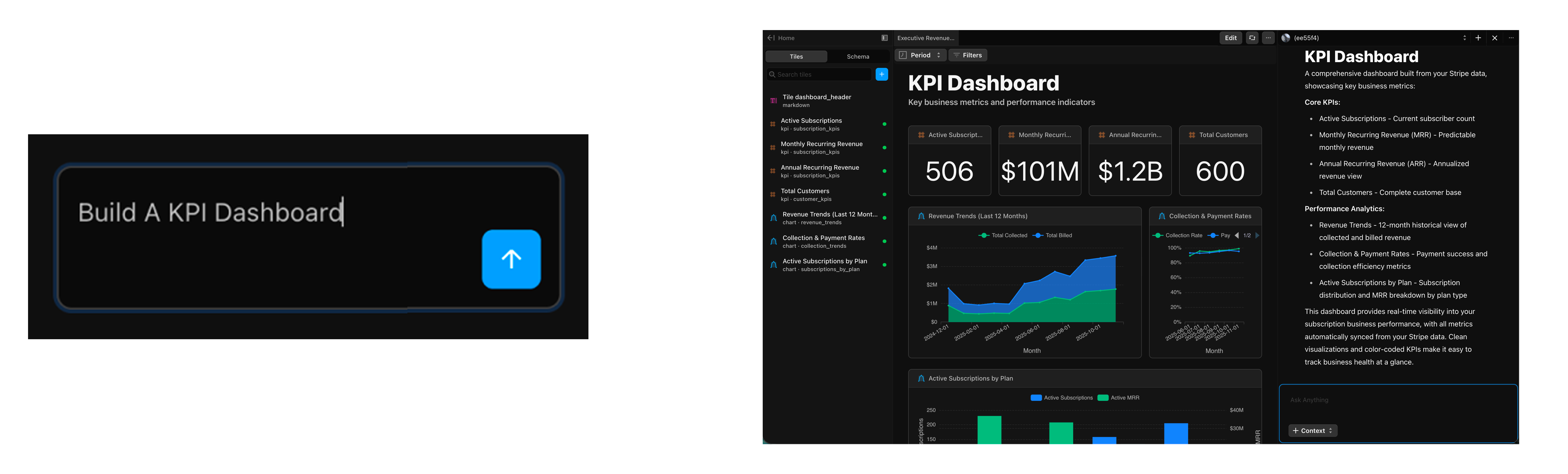
Fi finds the right data, builds the dashboard, and you can customize everything it creates. You can review the SQL or adjust the charts.
The difference: Fi actually understands your data because the semantic layer is built in, not bolted on. When you ask about churn, Fi knows your definition of churn. When you ask about revenue, Fi knows which Stripe fields to use and how to handle refunds. No guessing.
What used to require a data engineer, a week of setup, and ongoing maintenance now takes 30 minutes and works out of the box. One Series A SaaS company consolidated from five separate tools onto Definite and cut their analytics spend from $2,400/month to $250/month. A 40-person e-commerce team went from 15-second dashboard loads to sub-second queries.
What questions still go unanswered?
Enter your domain and we'll show you the business questions your current tools should be answering - and why they probably can't.
Try it with any company domain — no signup required.
What To Do
If you're an early-stage startup: Don't recreate the 2020 playbook. Start AI-native from day one. Connect your core data sources (CRM, payment processor, product database), start asking questions, and add complexity only if you actually need it. (We wrote a step-by-step setup guide that walks you through exactly what to connect, in what order, and how long each step takes.)
The first step: sign up, connect Stripe and your CRM, and ask for a revenue dashboard. You'll have it in 30 minutes. That's your proof of concept.
If you've already invested in the modern data stack: You don't have to rip everything out. But ask yourself: Where can you consolidate? Where is time-to-insight slowest? Start there. If you're evaluating warehouse alternatives specifically, our Snowflake alternatives comparison covers BigQuery, Redshift, and Databricks, our BigQuery alternatives guide walks through when to optimize, swap, or replace the whole stack, and our warehouse cost guide breaks down what you're actually paying.
The first step: identify one report or dashboard that's painful to maintain or slow to update. Rebuild it in an AI-native tool. Compare the time-to-insight and the maintenance burden. That comparison will tell you whether consolidation is worth it.
When to Stay vs. When to Move
| Stay with Modern Data Stack | Move to AI-Native |
|---|---|
| Dedicated data team (3+ people) | No data team, or 1-2 people |
| Current stack working well | Insights take days or weeks |
| Petabytes of data | Gigabytes to terabytes |
| Need custom ML models | Need standard analytics |
Who Is This For?
- Founders and executives evaluating data infrastructure decisions
- Data leaders questioning whether their current stack complexity is worth it
- Startups who haven't committed to a data stack yet
Get Started
Try Definite free and go from raw data to live dashboards in under 30 minutes.
- See connectors: definite.app/connector-db
- View pricing: definite.app/pricing