Supabase ETL: The Four Ways Out of Your Database (and What Breaks)

In February 2024, a Supabase user opened a discussion thread titled "Why so many issues replicating data to other DBs with CDC tools?" After weeks of failed attempts — Fivetran, Datastream, Estuary, Stitch, Airbyte — the closest thing to success was an Airbyte sync that worked except for one detail: it silently missed every deleted row. He was ready to leave Supabase over it.
Twenty-two months later, Supabase shipped the answer themselves: Supabase ETL, a first-party replication pipeline. The official answer now exists — and most of what ranks beneath it predates the product. What nobody has published in the six months since launch is a look at the actual decision: four real ways to get data out of Supabase, each with a different thing that breaks at 2 a.m., and a destination question that matters more than any of them.
That's this post. The short version: pick your pipe by blast radius, not by latency — and notice that the pipe was never the hard part.
The short version
- Supabase ETL is real and it's the eventual default — but it's in private alpha (as of June 2026), behind a request form, with two destinations (BigQuery and Iceberg Analytics Buckets) and no transforms. If you're in the alpha and BigQuery is your destination, use it.
- You have four ways out of Supabase: Supabase ETL, a managed CDC tool (Fivetran/Airbyte/Estuary), DIY logical replication, or scheduled incremental sync off a read-only credential. They differ less in features than in what breaks — alpha churn, mode misconfiguration, slot invalidation, or missed hard deletes, respectively.
- You probably don't need streaming. Supabase ETL advertises latency in milliseconds; your growth dashboard updates hourly at most. Sub-minute freshness is a requirement people assume, not one anyone asked for.
- The pipe is a weekend; the platform is forever. Whatever lands — Iceberg files in a bucket, raw tables in BigQuery — isn't analytics yet. Someone still owns the warehouse, the modeling, the metric definitions, and the BI on top. That someone is you, unless you pick a destination where those already exist. That's the case Definite is built for.
What Supabase ETL actually is (status: June 2026)
Supabase ETL launched on December 2, 2025 — a Rust change-data-capture framework (it began life as pg_replicate) that reads your database's logical replication stream and writes it to analytical destinations. The pieces worth knowing, all from Supabase's own materials:
- Status: private alpha. Access is by request form or account manager. Self-hosted Supabase: not available (the DIY paths below still apply there).
- Destinations: BigQuery and Analytics Buckets (Supabase's Iceberg-backed columnar storage, itself in public alpha). The launch named BigQuery only; Buckets arrived after. Snowflake is not a managed destination yet — though a Snowflake module already exists in the open-source framework, so expect that to change. Today, Snowflake users reach Bucket data only indirectly, via Iceberg external tables.
- Pricing: $25 per connector per month, plus $15 per GB of change data. The initial copy is free. On a high-churn events table, do that multiplication before you commit.
- It replicates as-is. No transforms. Tables must have primary keys. Custom types arrive as strings; generated columns don't arrive at all. Schema changes were not propagated at launch; as of June 2026 the open-source framework applies simple column adds, drops, and renames for some destinations, while type changes and other DDL still aren't — and the product page lists DDL support as "in development."
- It touches your WAL. During the initial copy, changes accumulate in the write-ahead log and replay once streaming begins — the first-party pipe has a production footprint too.
None of this is criticism. It's an alpha behaving like an alpha, from a team that clearly understands the problem — they built it because threads like the one above kept happening. The question is what you do now, and that depends on what you're willing to have break.
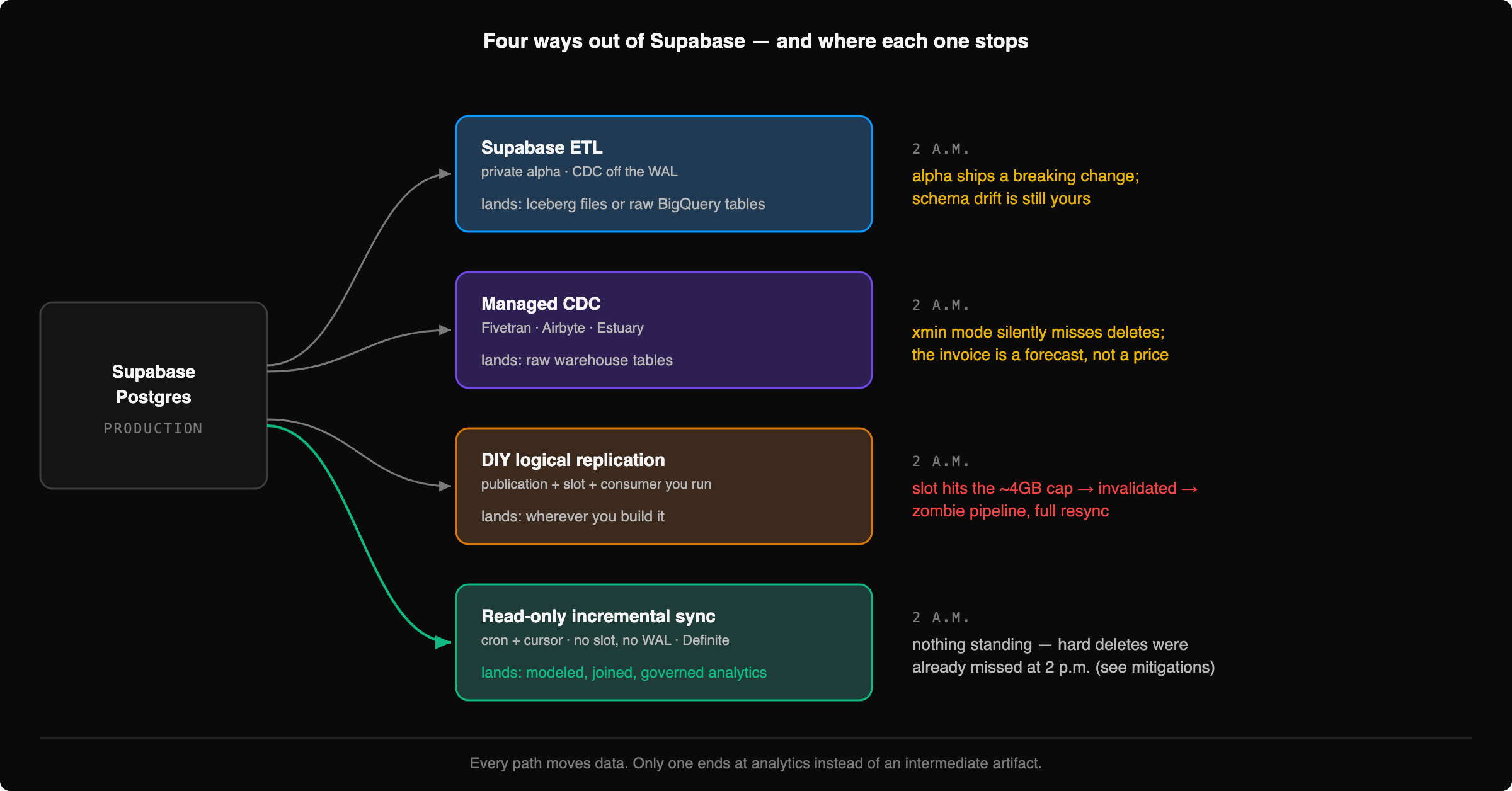
The four ways out, ranked by what breaks at 2 a.m.
A note on two paths you'll see ranking for these searches that don't belong on the list: foreign data wrappers go the wrong direction (they query a warehouse from Postgres — and the Snowflake wrapper has had an open error issue since late 2024), and read replicas scale reads without ever leaving Postgres. Neither moves your data anywhere.
Path 1: Supabase ETL — breaks on alpha velocity
If you're in the alpha and your destination is BigQuery or Iceberg, this is the closest thing to a native answer, and it captures everything logical replication captures — inserts, updates, and deletes. What breaks: the product is moving fast underneath you. Destinations, pricing, and schema-change behavior have all shifted in six months. Schema drift is still partly your problem, transforms are entirely your problem, and "private alpha" means your pipeline's roadmap is someone else's sprint planning.
Good for: alpha participants with BigQuery or Iceberg destinations who can absorb breaking changes.
Path 2: Managed CDC tools — breaks on configuration you own
Fivetran, Airbyte, and Estuary all replicate Postgres competently — when configured correctly. The failure mode is the configuration. Airbyte's xmin mode, the path of least resistance, cannot capture deleted rows — Airbyte's own docs say so — which is exactly what bit the engineer in that 2024 thread. The fix (logical-replication CDC mode, a direct connection rather than the pooler, the $4/month IPv4 add-on) is well documented and nobody reads it until after the incident.
Cost is the other 2 a.m. surprise, though be precise about why: Fivetran's MAR pricing counts each distinct row once per month no matter how many times it changes. The unpredictability isn't multiplication — it's that you can't forecast how many distinct rows your app touches, every insert on an event table is a new active row, and the per-MAR rate itself is a volume-tiered quote, not a price list.
Good for: teams with an existing warehouse and the attention budget to own connector configuration (tool-by-tool Postgres ETL rundown here).
Path 3: DIY logical replication — breaks on the slot
The engineer's answer, and the primitive underneath paths 1 and 2:
create publication analytics_pub for table public.orders, public.users;
-- consumer connects with a replication slot and tails the WAL
Here's the failure mode everyone half-remembers from vanilla Postgres: your consumer stalls, the replication slot pins WAL, the disk fills, production goes down. On Supabase, that specific disaster is actually fenced off — the platform caps slot WAL retention at roughly 4GB, not user-configurable. What happens instead is quieter and almost worse: exceed the cap and Supabase invalidates your slot. Your database survives the night. Your pipeline is silently dead, and the fix is a full resync. You've traded an outage for a zombie.
Add the operational details — direct connection only, IPv4 add-on, monitoring the slot, handling schema changes yourself, plus the consumer process you now run forever — and this path is a part-time job pretending to be a weekend project.
Good for: teams with real streaming requirements and someone on-call who knows what wal_status: lost means.
Path 4: Scheduled incremental sync — breaks on deletes (and we'll get to that)
The boring option: a read-only database user, a connection string, an initial full copy, then incremental pulls of changed rows on a cron — keyed on a cursor column like updated_at where one exists, with full refresh as the fallback for tables that lack one.
create role analytics_reader with login password '...';
grant select on public.orders, public.users to analytics_reader;
What's notable is everything this doesn't involve. No replication slot, so there's nothing to invalidate. No WAL hooks, no direct-connection requirement, no IPv4 add-on, no pooler workarounds. To be precise rather than absolute: reads aren't free — the initial full copy is real load, and a long-running snapshot query can hold back vacuum like any other long transaction. But those are bounded, schedulable query costs (statement_timeout exists; run the first copy off-hours), not a standing mechanism that can kill your pipeline or pin your WAL. If the thing you actually fear isn't stale data but your analytics stack hurting prod, this is the path where that fear has the least to work with.
The honest cost of that simplicity is the next section, because it's real and you should hear it from us rather than discover it.
Good for: business analytics on hourly-to-daily freshness — which, if you check what your dashboards actually need, is probably you.
The comparison, honestly
| Supabase ETL | Managed CDC | DIY logical replication | Scheduled incremental | |
|---|---|---|---|---|
| What breaks at 2 a.m. | Alpha ships a breaking change | Mode misconfig (xmin misses deletes); surprise invoice | Slot invalidated → silent zombie pipeline, full resync | Nothing — deletes were already missed at 2 p.m. |
| Captures hard deletes | Yes | Yes in CDC mode; no in xmin mode | Yes | No — see mitigations below |
| Schema changes | Partial, in motion | Varies; migrations can break connectors | Yours | Yours if DIY; propagated automatically on Definite* |
| Prod footprint | Replication slot + WAL during initial copy | Slot (CDC mode) | Slot + consumer you babysit | Read-only queries on a schedule |
| Supabase-side setup | Alpha access | Direct connection, IPv4 add-on, mode choice | Direct connection, IPv4 add-on, publication, monitoring | A connection string |
| Cost shape | $25/connector + $15/GB changes | Tiered MAR quote / infra you run | "Free" + your hours | Your hours if DIY; on Definite, no separate pipe cost — the connector is a feature of the platform* |
| Destinations | BigQuery, Iceberg Buckets (Snowflake coming) | Wide | Wherever you build | Wherever you point it; Definite's lakehouse* |
| What lands | Raw tables / Iceberg files | Raw tables | Whatever you built | Raw tables if DIY; modeled + joined on Definite* |
* Path 4 is a pattern you can DIY (cron + cursor query gets you raw tables and manual schema handling) or get as a managed platform — the starred cells describe Definite's implementation, graded separately so the comparison stays honest.
What the boring option gives up — said plainly
We just spent a section noting that Airbyte's xmin mode misses deletes. Scheduled incremental sync — including Definite's Postgres connector, which is what path 4 describes — misses hard deletes too, for the same architectural reason: a cursor query on updated_at can't see rows that no longer exist. CDC-based delete capture is on Definite's roadmap; it isn't shipped today. Same standard, applied to ourselves.
What makes this manageable in practice:
- Many Supabase schemas already soft-delete. RLS doesn't require
deleted_atcolumns, but audit-friendly app patterns tend to produce them — and where they exist, incremental sync captures every "delete" perfectly. Check your schema before assuming either way. - Periodic full refresh of delete-prone tables (they're usually the small ones: users, subscriptions) bounds the drift to the refresh interval.
- Append-only tables — events, orders, logs, the tables that make analytics heavy — don't delete, and aren't affected at all.
The other trade: it's a cron, not a stream. Syncs land on a schedule, not in milliseconds. Before you treat that as disqualifying, ask what consumes the data. If the answer is dashboards, weekly reviews, and a board deck, your freshness requirement is measured in hours — and "latency in milliseconds" is a spec-sheet number, not a requirement anyone in your company has actually stated. (If you're building user-facing real-time features, you're a different reader: that's the embedded analytics problem, and none of these batch paths is your answer.)
The pipe is a weekend. The platform is forever.
Here's the part no connector page mentions: every path above ends with data somewhere, and none of them ends with analytics.
Iceberg files in a bucket need a query engine, and then a metrics layer, and then dashboards. Raw tables in BigQuery need dbt or its equivalent, then a BI tool, then auth for the BI tool, then someone who notices when Tuesday's schema migration quietly broke Thursday's board number. And your Supabase data alone can't answer the questions that prompted this project — revenue per cohort lives in Stripe joined with your app data, CAC lives in your ad platforms, churn risk lives in your CRM. The pipe was one decision. What you've actually signed up for is five.
We've watched this movie at enough startups to know the ending: the stack project stalls, and the engineer who built it becomes the permanent unpaid data team — the person who re-points dbt models after every migration, rotates the BI tool's credentials, explains why Monday's MRR doesn't match Friday's, and fields "can you just pull…" requests between sprint tasks. A year later somebody asks why the "two-week" analytics setup is slow, brittle, and unowned. If you have a data team and real scale, building the warehouse stack is a legitimate path. If you're a founding engineer with a day to spend, it's the failure mode wearing a project plan.
Doing it with Definite
Definite is path 4 with the destination already built. Concretely:
- Connect Supabase as a Postgres source — the read-only credential and connection string from above, pasted into Settings → Integrations. No slot, no IPv4 add-on, no pooler gymnastics. (One Supabase-specific nicety: enable
pg_stat_statementsfrom the Supabase UI and Definite's AI can learn from your query patterns.) - Data lands in an open lakehouse next to your other sources — Stripe, HubSpot, ad platforms — synced on the schedule you set. Schema changes in your Supabase database propagate automatically: new columns show up, sensible type changes follow.
- Metrics get defined once in a governed semantic layer, and everything — dashboards, Fi, agents over MCP and API — reads from the same definitions. The Monday-versus-Friday MRR problem stops existing, because there's exactly one definition for anything to disagree with.
The whole point is what you don't do afterward: no warehouse to administer, no dbt project to own, no BI tool to wire up, no pipeline to babysit. Boring pipe, finished destination — teams connecting a source this way are typically looking at days to their first real dashboards, not the weeks-to-months of the assemble-it path.
The exit door is Iceberg
The fair objection to any platform: am I trading the stack-assembly trap for a lock-in trap?
Check the formats. Definite's store is open Parquet, Iceberg-interoperable, and can live in a bucket you own from day one — and if your concern is deployment topology rather than formats, the VPC/your-own-cloud conversation exists too. The interoperability runs both directions: Definite can attach external Iceberg REST catalogs and read and write them — the same standard interface Supabase's Analytics Buckets expose.
That has a practical near-term meaning. If you're in the Supabase ETL alpha streaming into Buckets, the zero-copy architecture — Supabase writes Iceberg, Definite attaches the catalog and queries it without re-syncing — is real today, caveat that the Supabase half carries an "expect breaking changes" label. As both halves mature, that's the open-format endgame this ecosystem is converging on: your data in standard table formats, every engine a guest, no engine a landlord.
Your data stays yours, in formats DuckDB can read from a browser tab. That's what an exit door looks like.
FAQ
Is it safe to run a replication slot against managed Supabase?
Safer than vanilla Postgres, with a twist: Supabase caps slot WAL retention (~4GB, not configurable), so a stalled consumer can't fill your disk — instead your slot gets invalidated and your pipeline dies needing a full resync. Monitor wal_status or pick a path without a slot.
Do I need CDC for analytics dashboards? If they refresh hourly or daily — the honest answer for most internal analytics — no. Scheduled incremental sync covers it. You need real CDC when you need deletes captured row-by-row or sub-minute freshness, which usually means a user-facing feature, not a dashboard. (For the fuller where-should-analytics-live argument, see where your Supabase analytics queries should actually run.)
How does incremental sync handle deleted rows? It doesn't see hard deletes — only CDC does. Soft-delete columns (which most Supabase apps using RLS already have) sync fine, and periodic full refreshes of small delete-prone tables bound the gap. Definite captures inserts, updates, and schema changes today; CDC delete capture is on the roadmap.
Is Supabase ETL production-ready? It's a private alpha (as of June 2026) from a team that understands replication deeply. The mechanism is sound; the wrapper around it — access, destinations, pricing, schema handling — is still moving. Treat it as the eventual default, not the current one.
If I adopt Definite, can I get my data out later? Yes — open Parquet, Iceberg-interoperable, optionally in your own bucket, plus an attachable Iceberg REST catalog interface. Exit requires no migration project; the formats are the contract.
How long until dashboards, and what does this cost? The pipe is minutes; first real dashboards are typically a matter of days, not the weeks-to-months of assembling a stack. Pricing is flat platform pricing — published on the pricing page, with no per-row or per-GB metering on the connector — so the answer to "can the bill surprise us?" is the same as the answer to "can the pipeline hurt prod?": there's no mechanism for it.
Your Supabase data is one read-only credential away from being analytics instead of a project. Connect it to Definite — the pipe takes minutes, and the destination is already built.