The Best ETL Tools for PostgreSQL in 2026: A Decision Framework

If you Google "best ETL tools for PostgreSQL" in 2026, most of the top results recommend tools that no longer exist and if they do, many are on life support.
Blendo — acquired by RudderStack. Stitch — deprioritized under Qlik after the Talend acquisition. Xplenty — folded into Integrate.io. Meltano — acquired by Matatika.
The Postgres ETL landscape looks nothing like it did five years ago. The whole paradigm shifted: ETL (transform before loading) gave way to ELT (load first, transform in the warehouse). Open-source tools like Airbyte and dlt didn't even exist when those guides were written. AI-powered analytics wasn't a category. And the survivors are consolidating fast — Fivetran merged with dbt Labs, then acquired Census for reverse ETL and Tobiko Data (SQLMesh) for advanced transformations, racing to become an end-to-end platform.
The right Postgres ETL tool in 2026 depends entirely on who you are and what you're optimizing for. This guide is organized by that — not by alphabet. Updated for May 2026 with current pricing, the post–Fivetran/dbt-merger landscape, and recommendations by source→destination pair and team size.
TL;DR — Pick your stack
If you came here looking for a one-line answer for a specific source→destination pair, here it is. Each pick is justified later in the post.
- Postgres → Snowflake: Fivetran for managed CDC; Airbyte Cloud if you want the open-source-rooted alternative. Definite if you don't already own Snowflake — it skips the warehouse purchase entirely.
- Postgres → BigQuery: Fivetran or Airbyte Cloud both ship solid managed connectors. Google Datastream is the BigQuery-native option with tighter IAM. Definite if you'd rather have Postgres + your SaaS data in one platform without standing up BigQuery at all.
- Postgres → Redshift: Fivetran for hands-off managed CDC. AWS DMS if you're already deep in the AWS account. Airbyte (Cloud or self-hosted) for the open-source path most teams pick at this pair.
- Postgres → ClickHouse: PeerDB. Purpose-built for this pair — logical decoding, low latency, schema mapping handled.
- Postgres → Postgres replication: pglogical. Native extension, row/column filtering, free, battle-tested in enterprise Postgres shops.
- Open-source path, Python team: dlt. Pip install, write a pipeline as code, point it at any warehouse. Best AI-assisted developer experience of the OSS options.
- Open-source path, max connector breadth: Airbyte OSS — same 350+ connectors as Cloud, runs on your infra, requires DevOps capacity.
- No warehouse yet, want answers this week: Definite. Postgres + 500+ other sources, managed warehouse, BI, and an AI analyst in one platform — 30 minutes to first dashboard.
Last updated 2026-05-07. We track 9 tools in this guide; 5 of them have shipped material changes since 2024 — Fivetran's merger with dbt Labs, Fivetran's acquisition of Census for reverse ETL and Tobiko Data (SQLMesh) for transformation, Meltano's acquisition by Matatika, and Stitch's progressive deprioritization under Qlik. If a 2022 listicle ranks above this one in your search results, the picks are almost certainly stale.
The CDC + pricing reality
Most "best Postgres ETL" tables compare on type and "best for" — categories AI Overviews can already summarize from training data. The columns that actually matter when you're choosing are below: whether the tool does real CDC, what you'll actually pay in 2026, and how long it takes to get a usable sync.
| Tool | Postgres CDC? | 2026 starting price | Free tier | Time to first sync | Best source→dest pair |
|---|---|---|---|---|---|
| Definite | Source ingestion (managed) | $0 free / $250/mo Platform | Yes | ~30 min | Postgres + 500+ SaaS → managed DuckDB warehouse |
| Fivetran | Yes (logical replication) | MAR-based, consumption | Yes (limited MAR) | Hours | Postgres → Snowflake / BigQuery / Redshift |
| Airbyte Cloud | Yes | Credits-based, consumption | Free trial | Hours | Postgres → any warehouse |
| Airbyte OSS | Yes | $0 license + your infra | Yes (self-host) | Days (DevOps) | Postgres → Redshift / Snowflake / BigQuery |
| dlt | Yes (Python lib) | $0 (open source) | Yes | Hours (if you write Python) | Postgres → DuckDB / any warehouse, code-first |
| dbt | N/A — transform only | Core: $0; Cloud: paid tiers | Yes (Core) | Pairs with EL tool | Any warehouse — runs the T |
| PeerDB | Yes (logical decoding) | $0 OSS + Cloud tier | Yes | Hours | Postgres → ClickHouse |
| pglogical | Native logical | $0 (PG extension) | Yes | Hours | Postgres → Postgres / Kafka |
| Meltano (Matatika) | Yes (Singer taps) | OSS + hosted plans | Yes (OSS) | Days | Custom / non-standard sources |
Specific dollar figures are deliberately omitted where vendors price per consumption — guessing the wrong number is worse than telling you to check the Fivetran pricing page or Airbyte pricing page yourself. The shape of each pricing model is what matters at the evaluation stage.
If You Want Answers Tomorrow, Not Next Quarter
For startups and SMBs, the real cost of ETL isn't the tool — it's the time, complexity, and engineering burden of assembling a multi-tool pipeline. You need an ETL/ELT tool, a warehouse, a BI platform, maybe a semantic layer, maybe dbt — and someone to maintain all of it. That's the problem all-in-one platforms solve.
Definite
Definite replaces the assembled Fivetran + Snowflake + Looker + dbt stack with a single platform: 500+ connectors (including Postgres as a source), a managed warehouse on DuckDB's columnar engine, a governed semantic layer via Cube.dev, dashboards, and Fi (an AI analyst that answers plain-English questions). Setup is ~30 minutes. No data engineer required.
If your Postgres database is a source of data (not your analytics warehouse), Definite ingests it alongside everything else your business runs — no separate ETL tool in the picture.
Should you use Postgres as your data warehouse? We Love Postgres. We'd Never Use It as a Data Warehouse. Postgres is phenomenal for OLTP. For analytics, purpose-built columnar engines are 10–100x faster.
Best for: Startups and SMBs that need insights fast, don't have a data engineer, and want one platform instead of four.
If You Want Managed Pipelines Without Building Everything
If you already have a data warehouse (Snowflake, BigQuery, Redshift) and a BI tool, you may just need a reliable way to move data from Postgres to that warehouse. That's where managed ELT platforms come in.
Fivetran
Fivetran is the market leader in managed ELT. Its Postgres connector uses Change Data Capture (CDC) via logical replication, meaning it reads your write-ahead log instead of querying your production database. Updates stream in near real-time with minimal load on your source, though row-based pricing leads many teams to weigh cost-effective Fivetran alternatives.
- 500+ connectors, fully managed and maintained
- Automatic schema drift handling — Fivetran adapts when your source tables change
- Pre-built analytics-ready data models for common sources
- Recently merged with dbt Labs, combining ingestion and transformation under one company
The caveat: Fivetran uses Monthly Active Rows (MAR) pricing. A sudden spike in source data or a high-volume connector can significantly increase your bill. And Fivetran is just the ingestion layer — you still need a warehouse ($200-500/month), a BI tool ($200-500/month), and potentially a semantic layer. The full stack cost adds up fast.
Best for: Data teams with an existing warehouse and budget for consumption-based pricing who want reliable, zero-maintenance data movement at scale.
Airbyte Cloud
Airbyte started as an open-source project and has grown into one of the two dominant ELT platforms. Airbyte Cloud is the managed version — you get the same connector catalog without running infrastructure.
- 350+ connectors with strong Postgres source and destination support
- Credits-based pricing (more transparent than MAR, but still usage-dependent)
- Growing community, active connector development
- Option to start on Cloud and migrate to self-hosted later if costs matter
The caveat: Same as Fivetran — Airbyte Cloud moves data but doesn't store or visualize it. You're still assembling a multi-tool stack.
Best for: Teams that want managed ELT with the flexibility to self-host later, and who are comfortable building the rest of the stack.
A Note on Stitch
You'll still see Stitch recommended in older guides. Stitch was acquired by Talend in 2018, Talend was acquired by Qlik in 2023, and Stitch has been progressively deprioritized since. Its free tier was eliminated, feature investment has stalled, and many users have migrated to Fivetran or Airbyte. If you're evaluating tools today, look elsewhere.
If You Have Engineers and Want Control
Some teams want — or need — to own their data pipelines. Maybe you have non-standard sources, strict compliance requirements, or simply prefer code over configuration. Here's what the code-first landscape looks like in 2026.
dlt (data load tool)
dlt is a Python-first, lightweight ELT library that's become the fastest-growing open-source data loading tool. It's designed for Python developers who want to write pipelines as code without the overhead of a platform.
import dlt
pipeline = dlt.pipeline(
pipeline_name="pg_pipeline",
destination="duckdb",
dataset_name="my_data",
)
pipeline.run(my_postgres_data)
pip install dltand go — no backends, no containers, no orchestration platform required- Works inside Jupyter notebooks, Cursor, and any AI code editor
- 8,800+ supported sources — many generated via LLM-assisted pipeline building
- 3M+ PyPI downloads, 6,000+ companies in production
- Backed by Bessemer Venture Partners
dlt is purpose-built for the era of AI-assisted development. You can describe a data source to an LLM, and it can scaffold a working dlt pipeline. That's a fundamentally different workflow than configuring connectors in a web UI.
Best for: Python-savvy teams who want to write pipelines as code, especially those leveraging LLMs for development.
Airbyte OSS (Self-Hosted)
Airbyte's open-source version gives you the same connector catalog as Airbyte Cloud but running on your own infrastructure.
- Full control over data — nothing leaves your network
- Free forever (you pay for infrastructure, not licenses)
- Same 350+ connectors
- Requires Docker or Kubernetes and ongoing ops maintenance
The trade-off: "Free" means free of license cost, not free of engineering time. You'll need someone to handle deployment, upgrades, monitoring, and scaling. For teams with DevOps capacity, it's a strong choice. For teams without, the hidden cost is real.
Best for: Engineering teams with DevOps capacity who want open-source flexibility and full data control.
dbt (data build tool)
dbt isn't an extraction tool — it's the transformation standard. Any modern Postgres ELT discussion has to mention it because dbt handles the T that extraction tools leave behind.
- Version-controlled SQL transformations
- Testing, documentation, and lineage built in
- Runs against your warehouse (Postgres, Snowflake, BigQuery, DuckDB)
- Recently merged with Fivetran — the implications of that consolidation are still unfolding
If you're using Fivetran, Airbyte, or dlt to load raw data into a warehouse, dbt is likely how you'll transform it into useful metrics and models.
Best for: Any team doing ELT that needs governed, version-controlled transformations. Essential middleware, not a standalone solution.
Target Postgres / Singer / Meltano
The Singer specification (originally from Stitch) defined a standard for ETL scripting: taps extract data, targets load it. Target Postgres from datamill-co was built as a Singer target for loading data into PostgreSQL.
The Singer ecosystem is still alive, but active development has largely migrated to Meltano (originally from GitLab, now independent). Meltano provides a modern CLI, orchestration, and managed Cloud offering on top of Singer taps and targets.
- Maximum flexibility — write custom taps for any source
- Maximum responsibility — you own the code, the orchestration, and the maintenance
- Meltano adds structure and deployability to what was previously a DIY scripting ecosystem
Best for: Teams with highly custom or non-standard data sources who are comfortable writing and maintaining pipeline code.
If You Need Specialized Replication
Some use cases don't need a general-purpose ETL platform — they need purpose-built replication between specific systems.
pglogical
pglogical is an open-source PostgreSQL extension for logical replication. Originally from 2ndQuadrant (now maintained by EDB after their 2020 acquisition), it enables:
- Postgres-to-Postgres replication with row and column filtering
- Streaming to Kafka and RabbitMQ subscribers
- Automatic replication of schema changes
- Partition-aware replication
pglogical isn't a general ETL tool — it's a replication layer for Postgres-native architectures. If you're running multiple Postgres instances and need to keep them in sync, or you need to stream Postgres changes into a message broker, pglogical is purpose-built for that.
Best for: Enterprise Postgres shops that need real-time replication between Postgres instances or into streaming systems like Kafka.
PeerDB
PeerDB is purpose-built for Postgres-to-ClickHouse CDC replication. If your analytics engine is ClickHouse (increasingly popular for real-time analytics at scale), PeerDB handles the bridge:
- Uses Postgres logical decoding for real-time Change Data Capture
- Optimized specifically for the Postgres → ClickHouse pipeline
- Handles schema mapping, type conversion, and incremental syncing
- Low-latency replication designed for analytics workloads
Best for: Teams running ClickHouse as their analytics engine who need fast, reliable Postgres replication without building custom CDC pipelines.
How to Choose: The Decision Framework
The Postgres ETL landscape has consolidated dramatically. In 2019, you had 11+ point tools to evaluate. In 2026, the real question is how much infrastructure you want to own.
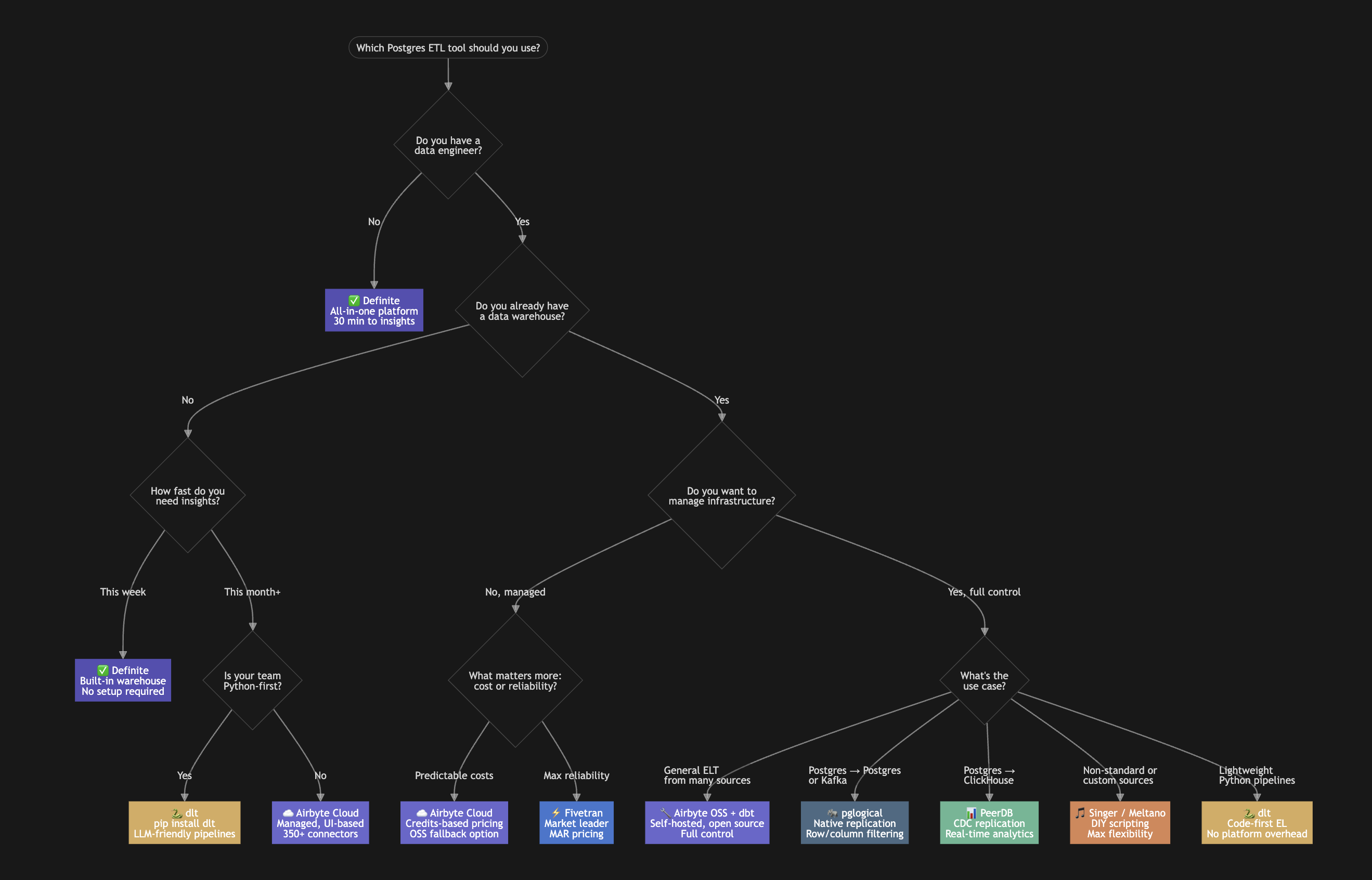
| Your Situation | Best Starting Point | Time to First Insight |
|---|---|---|
| Startup, need insights fast, no data engineer | Definite | 30 minutes |
| Have a warehouse, want managed no-code pipelines | Fivetran or Airbyte Cloud | Days to weeks |
| Python team, want lightweight code-first EL | dlt | Hours to days |
| Eng team, want full open-source control | Airbyte OSS + dbt | Days to weeks |
| Need Postgres → Postgres replication | pglogical | Hours |
| Need Postgres → ClickHouse | PeerDB | Hours |
| Maximum DIY, non-standard sources | Singer/Meltano + Target Postgres | Days |
The pattern is clear: the less infrastructure you want to manage, the faster you get to insight — but the more you pay in platform fees. The more control you want, the more engineering time you invest.
For most startups and SMBs, the math favors the all-in-one approach. The "free" open-source path often costs more in engineering time than a managed platform. But for engineering-heavy organizations with specific requirements, the code-first and specialized tools are genuinely excellent — and better than they've ever been.
What could your data tell you?
Enter your domain and we’ll show you the business questions your tools can already answer — you just can’t ask them yet.
Try it with any company domain — no signup required.
FAQ
What's the best ETL tool for moving Postgres data to Snowflake in 2026? Fivetran is still the default for managed Postgres → Snowflake CDC; the connector reads your write-ahead log via logical replication and handles schema drift automatically. Airbyte Cloud is the credible open-source-rooted alternative. If you don't already own Snowflake, Definite sidesteps the question entirely with a managed DuckDB warehouse, 500+ connectors, and BI all in one platform.
What's the best ETL tool for Postgres → Redshift? For most teams: Fivetran (managed, hands-off) or Airbyte (Cloud or self-hosted). AWS DMS is the cheapest path if you're already deep in the AWS account and willing to operate it. The choice usually comes down to whether you'd rather pay a vendor or pay an engineer.
What's the best ETL tool for Postgres → BigQuery? Fivetran and Airbyte Cloud both ship solid managed connectors. Google's own Datastream is the BigQuery-native option with tighter IAM and lower latency for change events. dlt is the Python-first alternative if you'd rather write the pipeline as code and skip the SaaS bill.
What's the best open-source ETL for Postgres? Three real options in 2026: Airbyte OSS (broadest connector catalog, requires Docker/Kubernetes and ongoing ops), dlt (lightweight Python library, AI-assisted pipeline scaffolding), and Meltano under Matatika (best fit for non-standard sources via Singer taps). For Postgres → Redshift specifically, Airbyte OSS is the most popular pick we see.
Should I use Postgres itself as my data warehouse? Almost never. Postgres is excellent at OLTP (transactional workloads); columnar engines like DuckDB, Snowflake, and BigQuery are 10–100x faster on analytical queries at any meaningful data size. We wrote a longer breakdown: We Love Postgres. We'd Never Use It as a Data Warehouse..
How much does Fivetran cost for Postgres CDC? Fivetran uses MAR-based pricing — you pay per Monthly Active Row, with a free tier for low volumes. Real-world Postgres CDC bills depend heavily on your write volume and how many tables you sync; bills frequently surprise teams in the months after rollout. Most teams that price-shop end up evaluating Fivetran alternatives once monthly bills move past four figures.
Can I do Postgres ETL without a warehouse at all? Yes — if your endpoint is analytics, not data movement. All-in-one platforms collapse the ETL + warehouse + BI stack into a single product. Definite ingests from your Postgres database directly into a managed warehouse with BI, semantic layer, and an AI analyst built in — total cost $0–$250/mo against $9,500+ for the assembled stack.
The Definite Advantage
If you've read this far and thought "I just want to connect my Postgres database and start getting answers" — that's what Definite is built for. One platform: 500+ connectors (Postgres included), a managed DuckDB warehouse, a governed semantic layer, dashboards, and Fi (an AI analyst you can ask plain-English questions). Built on open standards (DuckDB, Iceberg/Parquet, Cube.dev) so your data and queries are portable.
Get started with Definite — 30 minutes from signup to your first Postgres dashboard. Or request a demo to see how it compares to assembling Fivetran + Snowflake + Looker yourself.