Duck Lake vs Iceberg: An Operator's Take After a Year in Production

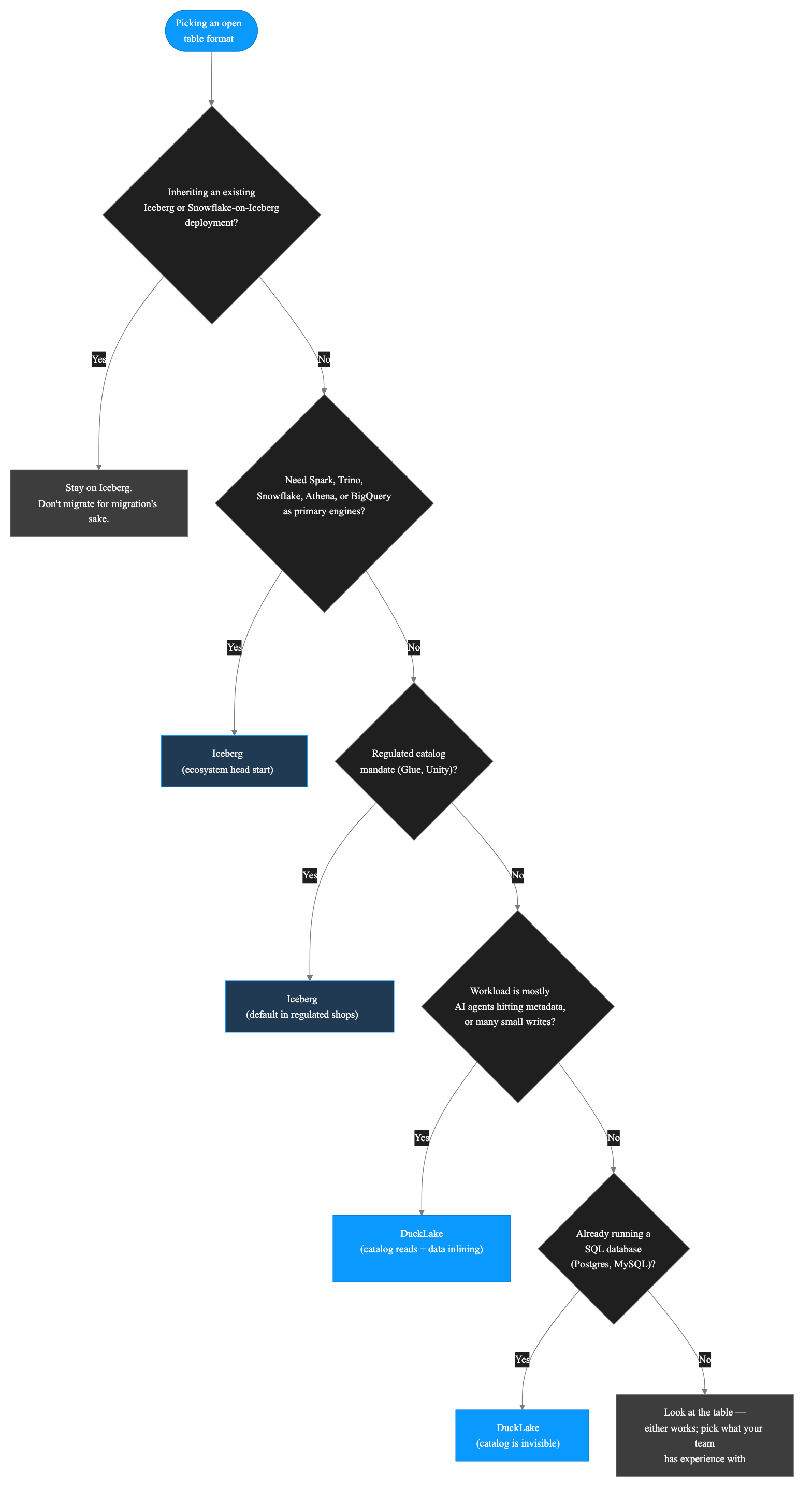
I run DuckLake in production at Definite; the operational rationale is in our DuckLake business case. I'd make the same call again tomorrow. But if you're inheriting a Snowflake-on-Iceberg deployment, or your roadmap has Spark and Trino as primary query engines, I'd tell you to stay on Iceberg — and any post that doesn't say so plainly is selling you something.
I just did a LinkedIn Live with Alex Merced (Head of DevRel at Dremio, co-author of Apache Iceberg: The Definitive Guide and the upcoming Architecting a Lakehouse from Manning), and we agreed on more than Google does for "duck lake vs iceberg" would have you believe. This post is what I wish that conversation had been written down as: a verdict, a decision table you can paste into Slack, a section on where I think Iceberg still wins, and the questions I'd ask a vendor that runs either format under the hood.
The short version:
- DuckLake (DuckDB Labs, May 2025; v1.0 April 2026) stores table metadata in a SQL database. Apache Iceberg (Netflix, 2017) stores metadata as JSON/Avro files on object storage and depends on a separate catalog service.
- The data on disk is Parquet in both cases. The difference is where the metadata lives and what you have to operate.
- Pick DuckLake when: single-engine or DuckDB-centric stack, small to mid-scale (≤ low-TB), small data team, write workloads with many small commits, AI-agent traffic that hits the catalog often.
- Pick Iceberg when: multi-engine federation (Spark + Trino + Snowflake + Athena), petabyte-scale, regulated catalog requirements (Glue, Unity), or you've already standardized on it.
- Both formats are converging. DuckLake 0.3 shipped Iceberg interop; Iceberg's V4 spec is moving toward a metadata model that could fit DuckLake-style backends.
- Performance is engine-dependent, not format-dependent. The real choice is operational risk, not benchmark numbers.
The verdict, by data size
The most useful thing I can give you is a table. Find your row, read across.
| Workload tier | Format | Catalog | Engines I'd run | Watch out for |
|---|---|---|---|---|
| ≤ 100 GB, single team | DuckLake | A single Postgres, or even a DuckDB file | DuckDB / DuckLake-native (Definite, MotherDuck, native CLI, DataFusion) | If you'll add Spark or Trino later, plan the migration cost early |
| 100 GB – 5 TB, mostly one team | DuckLake | Postgres on managed RDS / Cloud SQL | DuckDB-centric + occasional read from Iceberg engines via interop | Sorted tables and bucket partitioning matter at this size — turn them on |
| 1 – 50 TB, multi-team but read-heavy | Either — depends on engine plans | DuckLake: Postgres. Iceberg: REST + Polaris/Lakekeeper | DuckLake if DuckDB-first; Iceberg if you need Spark or Trino | Iceberg's catalog ops burden becomes real at multi-team scale |
| 50 TB – 5 PB, multi-engine federation | Iceberg | REST catalog (Polaris, Lakekeeper) or Glue | Spark, Trino, Snowflake, Athena, BigQuery — pick anything | Manifest churn and small-write economics — plan compaction |
| 5 PB+, regulated, multi-region, multi-write-cluster | Iceberg | Whichever catalog your compliance team already approved | Whatever the broader org standardized on | This is Netflix territory — DuckLake wasn't built for it |
A note on the table: scale numbers are operational rules of thumb, not hard limits. The format choice is rarely about your bytes — it's about how many engines, teams, and write clusters touch them. If you're a single-team startup at 100 TB doing mostly DuckDB-style analytical work, DuckLake will serve you fine. If you're a 5-team org at 5 TB with three different query engines and a compliance catalog, Iceberg is the path of least resistance.
And if you pick DuckLake and want to switch to Iceberg later, the data on disk doesn't move — it's already Parquet. You'd export the catalog metadata, write it as Iceberg manifests, and point a catalog service at the result. It's a real project, measured in weeks not months, but it isn't a rewrite. The migration cost in either direction is bounded.
Why the catalog question is the actual question
Nobody actually cares about JSON-vs-RDBMS metadata for its own sake. What you care about is what you have to operate at 2am when something breaks. That's the catalog. Everything else flows from it.
Here's the design choice each format made.
Iceberg committed to file-based metadata. No required external dependency. You can put an Iceberg table on a bare S3 bucket and it works. The cost of that design freedom is that the catalog has to live somewhere, and "somewhere" turned into a five-year ecosystem race: AWS Glue, Apache Polaris (Snowflake's donation, now a top-level Apache project as of April 4, 2026), Lakekeeper, Project Nessie, Hive Metastore, Snowflake's managed catalog, the REST catalog spec. Each one is a service you operate, integrate engines with, and worry about.
DuckLake went the other way. It requires a database catalog from day one — Postgres, DuckDB, MySQL, or SQLite. That single dependency buys you two things: ACID guarantees come for free (transactions are how databases work), and data inlining — small writes land directly in the catalog database instead of producing tiny Parquet files. No compaction service. No tiny-file hygiene script. The lake stays clean by construction.
The interesting thing — and Alex pointed this out on the call — is that this isn't a weird new idea. BigQuery's metadata lives in Spanner. Snowflake's lives in FoundationDB. Both of the warehouses that defined the cloud-warehouse era already use the database-as-catalog pattern internally. They just don't expose it in open formats. DuckLake is the first lakehouse format that does.
So the trade is clean. Iceberg traded operational coupling for design freedom. DuckLake traded design freedom for operational simplicity. Both are reasonable. The question is which trade fits your team.

Why I picked DuckLake for Definite
Four reasons, in roughly the order of weight they had on the decision.
1. We were running a database anyway. Definite's stack already includes managed Postgres for product state. Adding a Postgres-backed DuckLake catalog cost us nothing operationally — and it gave us ACID semantics over the lake without adding a service. For a small team, "the catalog is just another schema in a DB we already run" is a meaningful unlock. DuckLake's own framing is that it's similar in shape to Delta Lake with Unity Catalog, or Iceberg with Lakekeeper or Polaris. Except the catalog is something you almost certainly already have.
2. The AI-agent angle. This is the one that's hard to find written down anywhere else, and it was the deciding factor for us. Definite is built around an AI agent that builds, modifies, and queries the lake. That means metadata gets touched orders of magnitude more often than in a human-driven workload. A human analyst might run fifty queries a day. An agent doing schema inspection, query planning, and iterative refinement runs thousands. Iceberg's metadata path walks a tree of S3 objects on every read; DuckLake's is a single SQL query against the catalog database. I haven't seen a third-party benchmark on agent workloads — the format is too new — but the architectural shape is unambiguous. At one human-per-day, the difference is invisible. At thousands of agent-driven queries per day per customer, it compounds. If your workload is mostly humans clicking dashboards, you won't notice. If it's mostly agents, you will. The cost-economics version of this argument — what running those agents on Snowflake actually costs in 2026, and where the architecture should sit instead — is in our companion post on AI agents and Snowflake bills.
3. Data inlining solves the small-write problem. Writes that would produce tiny Parquet files in Iceberg (and force a compaction layer) land in the catalog database instead. DuckDB Labs published a streaming benchmark in April 2026 showing 926× faster queries and 105× faster ingestion vs Iceberg on a streaming workload. That's a vendor benchmark, not third-party validated, so I don't lean on the exact numbers. But the architectural shape is unambiguous: Iceberg's small-file problem is real enough that Dremio — an Iceberg-camp company — maintains compaction guidance as a core operational concern, and DuckLake makes that concern go away by not creating the problem.
4. Hindsight in the design. DuckDB Labs got to design DuckLake from late-2024 problems forward, with the operational tradeoffs of every Iceberg deployment already visible. That's not a knock on Iceberg — Ryan Blue and Dan Weeks were solving Netflix's 2017 problems with the tools available at the time, and they got remarkably far. But the catalog ecosystem that grew on top of Iceberg is partly legacy: it solved Netflix's 2017 problem with the constraints of that era, and a few of those constraints don't apply anymore. Starting clean in 2025 produces a different shape.
I'd make the same call again tomorrow. But it's not the right call for everyone.
Where Iceberg still wins, no asterisks
If a post tells you DuckLake is better, and doesn't have a section like this one, close the tab. Here are the situations where Iceberg is the right answer.
1. Multi-engine federation. If you need Spark, Trino, Snowflake, Athena, and BigQuery to read the same tables today, Iceberg is the answer, full stop. Iceberg's engine ecosystem — Spark, Trino, Flink, Presto, Hive, Snowflake, Athena, BigQuery, ClickHouse (read), Dremio — has a five-year head start on tooling. DuckLake is catching up (the v1.0 release post lists clients for DataFusion, Spark, Trino, and Pandas), but it's not there yet, and it won't be for a while.
2. Already-Snowflake-on-Iceberg shops. Snowflake reads and writes Iceberg natively — both managed catalogs and external Iceberg tables. If you're paying Snowflake anyway and your data is already on Iceberg, the migration cost almost certainly outweighs the design wins. Don't migrate for migration's sake. (And if you're paying Snowflake but not on Iceberg, that's a different conversation.)
3. Regulated catalog mandates. If your compliance team has signed off on Glue or Unity Catalog as the system of record for table metadata, you don't get to swap in Postgres. That's not a technical decision; it's an audit decision. Iceberg is the default. The good news: Polaris, Lakekeeper, and the REST catalog ecosystem are mature enough that "the Iceberg catalog you can defend in an audit" is no longer a hard problem.
4. Multi-team / multi-write-cluster workloads. Iceberg's optimistic concurrency on object storage is a known, well-understood pattern, and it scales horizontally without any single coordinator. DuckLake's catalog database is a single point of write coordination — fine at low-to-mid scale, but a bottleneck you'd have to actively engineer around at the high end. If you have ten engineering teams writing to the same lake from different clusters, Iceberg is the safer bet.
5. The ecosystem. Tabular (acquired by Databricks for $1B in 2024) folded into Unity Catalog. Snowflake donated Polaris. AWS doubled down on Glue and Athena's Iceberg support. Every major data vendor has shipped Iceberg integrations because Iceberg is where the customers are. That's not going to flip in 18 months. If you want maximum optionality for the next five years, Iceberg has it.
I run DuckLake. I think the case for it is real. None of those facts about Iceberg change.
Which catalog you actually run, by format
If the catalog question is the actual question, here's what each format actually asks of you.
| Format | Catalog | Operational profile |
|---|---|---|
| Iceberg | AWS Glue | Managed by AWS. Cheap until it isn't. AWS-only. |
| Iceberg | REST catalog (Polaris, Lakekeeper, Nessie, Tabular before Databricks) | Stateless service in front of a metadata store. You run it. Heaviest ops burden, most flexibility. |
| Iceberg | Hive Metastore | Legacy. If you've already got one, fine. If not, don't start. |
| Iceberg | Snowflake-managed / Unity Catalog | Tightest integration; locks you to one vendor's catalog model. |
| DuckLake | Postgres | Use what you already have. Minimal ops. ACID for free. |
| DuckLake | DuckDB file | Single-machine or single-tenant only. Fine for dev. |
| DuckLake | MySQL / SQLite | Supported. Postgres is the path most operators take. |
The honest read: if you're not already running Postgres (or another supported DB), DuckLake's catalog story isn't free for you either — you're just deploying a Postgres instead of a Polaris. For most teams, the Postgres is already there.
What can read these formats today (and what's coming)
This is a moving target. As of May 2026, here's where things stand.
| Engine | Iceberg | DuckLake |
|---|---|---|
| DuckDB | ✅ via extension | ✅ native |
| DataFusion | ⚠️ via icelake | ✅ via Hotdata |
| Spark | ✅ read/write | ⚠️ via MotherDuck client |
| Trino | ✅ read/write | ⚠️ two community implementations (awitten1, brikk) |
| Snowflake | ✅ read/write (managed + external) | ❌ |
| Athena | ✅ read/write | ❌ |
| BigQuery | ✅ external tables | ❌ |
| Dremio | ✅ read/write | 🟡 community-driven |
| ClickHouse | ✅ read | ⚠️ early |
| Definite / MotherDuck | ✅ via DuckDB | ✅ native |
DuckLake's interop story (more on it in a moment) means some Iceberg engines can read DuckLake tables via the deletion-vector compatibility layer. The native non-DuckDB ecosystem is still narrow today. It will be wider in twelve months. It is not where Iceberg is.
Streaming is hard for both — and the V4 work matters
Sub-second freshness is hard for both formats today. On the Iceberg side, the V4 spec is in active development — Amogh Jahagirdar's Adaptive Metadata Tree restructures how metadata is committed and read, and Russell Spitzer's streaming-interface work targets micro-batch ingestion explicitly. Neither has shipped. Both will help when they do. On the DuckLake side, data inlining addresses the streaming small-write case directly. For genuine sub-second freshness on user-facing dashboards, you still want ClickHouse, Pinot, or Druid alongside the lakehouse, not instead of it.
The two formats are converging
This is the part of the story that doesn't fit on a vendor slide.
Both formats are, at the data layer, basically a list of Parquet files plus metadata. The data on disk is identical. If you point a Parquet reader at the underlying files, it doesn't know or care which catalog wrote them.
DuckLake 0.3 (September 2025) shipped Iceberg interoperability: you can COPY data — and table metadata — between DuckLake and Iceberg in either direction. It's not live cross-engine reads, but it's a real, scripted migration path that DuckLake 1.0 keeps and extends. The deletion vectors DuckLake writes are designed to be Iceberg-compatible.
On the Iceberg side, Alex's argument on the call was that the V4 spec work is moving toward a model where the catalog spec itself is more pluggable — and a DuckLake-style RDBMS-backed catalog could plausibly fit inside a future Iceberg spec without too much violence. Whether that actually happens depends on the politics of the V4 vote, but the architectural drift is real.
In eighteen months, the "DuckLake or Iceberg" question may be less load-bearing than it is today. The right move is to pick what fits your team now, knowing the migration cost in either direction is bounded. And if it turns out that V4 ends up absorbing DuckLake-style backends into the Iceberg spec, that's a good outcome for everyone — your data stays where it is, and the labels on the box change.
If you're evaluating a vendor that uses one or the other
Many readers aren't deploying this themselves. You're shopping a vendor — Definite, MotherDuck, a Snowflake-on-Iceberg shop — and you want to know whether their format choice is defensible and what your exit looks like if it isn't.
Here are the questions I'd put on the vendor call:
- What's the actual file layout on object storage? The data should be Parquet. If it's a custom format that only the vendor's engine can read, run.
- Can you give me read access to the underlying bucket? If yes, you can always leave with your data, regardless of what catalog they run.
- Where does the table metadata live, and can I export it? For Iceberg: which catalog, can you export manifest files. For DuckLake: which database, can you dump the schema.
- If I want to switch from your catalog to my own — Glue, Polaris, my own Postgres — what's the migration path? A real answer is "here's a script and an estimate." A bad answer is "we'd have to scope that."
- What engines can read this format today, and which are on the roadmap? Cross-check their answer against what you'd actually want to query with.
- If I want to leave, what's the cost in days? Push for a real number, not "easy."
For what it's worth, the short version of those answers from us at Definite: Parquet in your own bucket, metadata in Postgres you can export, open spec, tested COPY paths to Iceberg. If the vendor you're talking to can't give you answers in that shape, that's the signal.
How to actually pick
One important caveat first: this post reads like advice to someone choosing fresh. Most readers aren't. If you've inherited a Snowflake-on-Iceberg deployment or a Databricks/Unity setup, the question isn't "which format" — it's "what would I have to give up to switch." For most inheriting teams, the answer is too much. Stay where you are. The format wars converge anyway.
For everyone else, the decision criteria, ranked the way I'd weigh them:
- What engines you plan to query with. Hardest constraint. If your roadmap has Snowflake, Athena, BigQuery, Spark, or Trino as primary engines, Iceberg's ecosystem is doing more for you than DuckLake's will for the next year or two.
- How much your workload looks like an AI agent. Human-driven analytics, the metadata-lookup difference is invisible. Agent-driven, it compounds.
- What your team already runs. Postgres for years, DuckDB-friendly analytical work — DuckLake's catalog is invisible to you. Spark + Glue shop — Iceberg's path of least resistance is real.
- Catalog as a service or as a schema in a database. That's the ops burden trade. Either way, the Parquet on disk doesn't care which catalog wrote it — you can always walk.
FAQ
Is DuckLake production-ready?
Yes. DuckLake v1.0 shipped April 2026 with backward-compatibility guarantees. Definite has been running it in production for our customer base — see our DuckLake business case for the operational rationale. The risk that remains is ecosystem maturity — engine support, third-party tooling — not format stability.
Do I need to run a separate catalog service for Iceberg?
At any meaningful scale, yes. Some option (Glue, REST + Polaris/Lakekeeper, Hive Metastore, Snowflake-managed, Unity Catalog) has to be there. The "Iceberg on bare S3" pattern works for read-only or single-writer cases, but it doesn't survive concurrent writes or governance requirements at scale.
Can I read DuckLake tables with engines other than DuckDB?
Yes, but more narrowly than Iceberg. The DuckLake v1.0 release lists client implementations for DataFusion (Hotdata), Spark (MotherDuck), Trino (two community implementations), and Pandas. The native non-DuckDB ecosystem is real but smaller; DuckLake's Iceberg-compatible deletion vectors also enable some bidirectional COPY operations between formats.
If I pick DuckLake and want to migrate to Iceberg later, how hard is that?
The data on disk is Parquet — that part stays. You'd export the DuckLake catalog metadata, write it as Iceberg manifests, and point a catalog service at the result. It's a real project, measured in weeks not months, but it isn't a rewrite. DuckLake 0.3+ ships COPY operations to Iceberg that handle most of the migration mechanics for you.
Is DuckLake tied to MotherDuck or DuckDB the company?
DuckLake is an open spec maintained by DuckDB Labs (the foundation behind DuckDB). MotherDuck is one vendor in the ecosystem; Definite is another. The format is open, the metadata schema is documented and queryable, and the data on disk is standard Parquet. You're not locked into MotherDuck — or anyone — by picking DuckLake.
When should I not use Iceberg?
The most-cited limitation is wide tables — many sparingly-used columns. Iceberg's metadata model defaults to per-column statistics for ~100 columns and requires manual tuning beyond that. The operational small-file problem on high-frequency writes is the other well-known issue, addressed in DuckLake by data inlining and in Iceberg by compaction tooling and (eventually) the V4 spec work.
Bottom line
I picked DuckLake for Definite because we already run a database, our workload is AI-agent-heavy, and the design wins were real for the cohort we serve. I'd make the same call again. But Iceberg is the right call for Spark/Trino/Snowflake-federated workloads, regulated catalogs, and shops already on it — and a post that pretends otherwise is selling you something, not informing you.
The two formats are converging anyway. Pick what fits your team. If you want DuckLake without running the catalog, the engines, or the AI agent yourself, that's what we built Definite to be. If you'd rather run it yourself, the spec is open and the migration cost out of either format is bounded — pick what fits.