What Is a Data Lakehouse? An Operator's Field Guide

You probably already know the one-sentence answer: a data lakehouse puts a query engine on top of cheap object storage so you get warehouse features without loading everything into a warehouse. Lake economics, warehouse management, one system. Google's AI Overview will tell you the same thing, with a Bronze/Silver/Gold diagram, before you click anything.
So this is not that article. We run a data lakehouse in production at Definite. In May 2024 we moved our entire analytics stack off Snowflake to one: DuckDB for compute, open Parquet files in object storage, and a SQL catalog holding the table metadata. Every customer dashboard, every AI query, every pipeline runs on it.
Here is the short version of what running one taught us. A lakehouse used to have exactly one real disadvantage against a warehouse, and it was operational: the open table format underneath needs ongoing maintenance, and that work has to land on someone. That single fact is the honest reason most teams picked a warehouse instead. The moment a managed platform takes that work off your plate, the disadvantage disappears, and every other reason still favors the lakehouse. The rest of this piece is the field guide behind that claim: what a lakehouse actually is, which parts the vendor explainers leave out, and where the warehouse still wins.
The short version, if you only read this far
- For most teams, a managed lakehouse is now the better default than a warehouse. The lakehouse's one real disadvantage was that it was harder to operate. A managed lakehouse removes that and keeps the structural wins: open format, one copy for AI, storage you own.
- A data lakehouse is three separate layers pretending to be one product: object storage (the files), an open table format plus a catalog (the metadata that makes files behave like tables), and a query engine (the compute that reads them).
- Its real advantage is not "cheaper than a warehouse." It is one open copy of your data that many engines can read, including the AI tools you have not adopted yet. Lock-in moves from the storage format to the catalog, which is where you should actually be looking.
- The hidden cost is operations: an open table format needs ongoing compaction, snapshot cleanup, and schema management. Skip it and queries slow down and bills climb. Managed platforms do this work for you; roll-your-own means you do it.
- The honest exceptions: under ~1TB on pure BI with no AI workloads, a warehouse (or even Postgres) is still simpler, and at petabyte, multi-team scale you want a distributed lakehouse (Iceberg plus Spark), not the single-catalog kind described here. In the wide middle between those, the managed lakehouse wins.
If you want the full taxonomy first (database vs. lake vs. warehouse vs. platform), the broader piece is What Is a Data Platform?. A lakehouse is a storage architecture; a platform is the whole system built around one.
A lakehouse is three layers pretending to be one
The marketing presents the lakehouse as a single thing. Operationally it is three, and the most useful thing you can do before evaluating one is take it apart and ask who runs each piece.
| Layer | What it is | Who operates it |
|---|---|---|
| Object storage | Your data as open files (usually Parquet) sitting in S3, GCS, or Azure Blob. Cheap, durable, effectively infinite. | The cloud provider handles durability. You own bucket layout, lifecycle, and access. |
| Table format + catalog | The metadata layer that turns a pile of Parquet files into a real table with ACID transactions, schema enforcement, and time travel. This is Apache Iceberg, Delta Lake, or Apache Hudi, plus a catalog that tracks which files belong to which table. | Someone has to run compaction, expire old snapshots, and manage schema changes. That someone is you, or a managed service you pay. |
| Query engine | The compute that reads and writes the tables: DuckDB, Spark, Trino, Snowflake, Athena. Swappable, because the data underneath is open. | You (self-managed cluster or process) or a vendor (managed compute). |
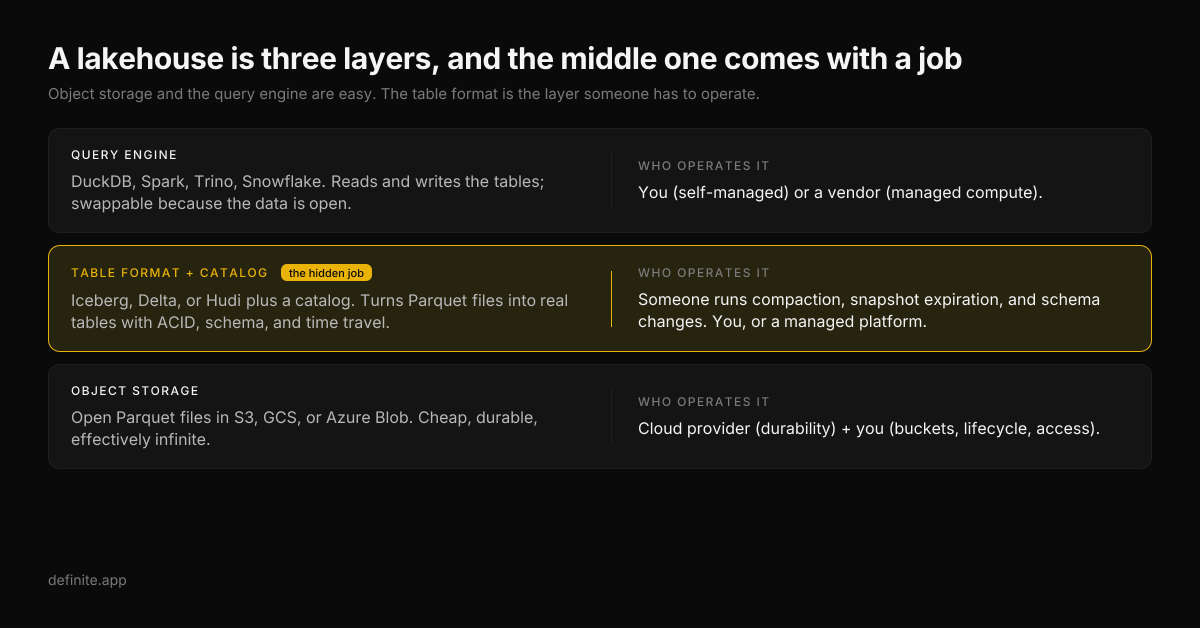
The single sentence to carry into any evaluation: a lakehouse is object storage plus an open table format plus a query engine, and the table-format layer has an operational owner whether or not anyone named one. Every glossy explainer covers layers one and three. The second layer, the one with the ongoing job attached, is the one nobody wants to talk about.
(One clarification, because it trips people up: the Bronze/Silver/Gold "medallion" model you see in most diagrams is a convention for organizing data within these layers, not a fourth layer. It is how you model, not how you store.)
The three table formats come from three companies solving the same problem: Delta Lake from Databricks, Apache Iceberg from Netflix, Apache Hudi from Uber. As of mid-2026 the momentum has consolidated hard around Iceberg, which every major cloud and query engine now reads. The format wars are mostly settling, and projects like Apache XTable now translate between Hudi, Delta, and Iceberg, so the choice is less of a one-way door than it was two years ago. If you want the deep comparison, we wrote one: Duck Lake vs Iceberg.
The hidden job: someone has to operate the table format
Here is the part that does not make it into the benefits list. "Just put Iceberg on S3" sounds like a free architecture. It is not. An open table format is a living thing that needs maintenance, and if you run it yourself, the maintenance is your job.
Every write to an Iceberg or Delta table creates new files and a new snapshot. A streaming source can produce hundreds of small files an hour. Left alone, two things happen. First, the small-files problem: your query engine has to open thousands of tiny files instead of a few big ones, and the overhead is brutal. Second, metadata bloat: snapshots accumulate forever unless you expire them, and the catalog slows down.
This is not theoretical, and the numbers are large. AWS benchmarked an Athena query against 582,000 small files at 40 seconds; after compacting those into 336 right-sized files, the same query ran in 9.7 seconds, roughly 75% faster. Glovo reported a 10x cost reduction on heavily queried tables, mostly from fewer S3 GET requests. Reading a million small files can cost a thousand times more in API calls than reading a thousand properly sized ones.
The fix is routine table maintenance, defined in the Apache Iceberg docs: compaction (rewrite small files into big ones), snapshot expiration (delete old metadata), orphan-file cleanup. None of it is hard. All of it is ongoing, and it is the line item every "lakehouse is cheap" pitch quietly omits.
This is the whole game: the operational burden is the only honest reason most teams chose a warehouse over a lakehouse. Everything else favored the lakehouse. Remove the burden and the calculus flips. And the maintenance, while unavoidable, does not have to be yours. Managed platforms increasingly run it automatically: Databricks made Predictive Optimization the default for its managed tables in 2025, and AWS S3 Tables does continuous compaction out of the box. At Definite we run compaction, snapshot cleanup, and schema management underneath the customer's lakehouse, so the open copy and the query speed are theirs and the runbook is ours. Either a managed platform is running compaction for you, or your team is. There is no third option, and the whole appeal of a lakehouse evaporates the moment that job lands on someone who did not plan for it.
Lakehouse vs. warehouse, with the downsides left in
A comparison table where the new thing wins every row is a sales asset wearing an explainer costume. Real architectures have tradeoffs. Here is the version with the lakehouse's weaknesses left in.
| Data warehouse | Data lakehouse | |
|---|---|---|
| Storage | Proprietary internal format. Fast, but the data lives in the vendor's house. | Open files (Parquet) in your own bucket. Portable, but you arrange them. |
| Setup | Load data, write SQL, done. Genuinely turnkey. | More moving parts: storage, format, catalog, engine. Newer and less turnkey. |
| Performance | Excellent on structured data; heavily optimized out of the box. | Excellent when maintained; degrades without compaction. You earn the performance. |
| Workloads | BI and SQL analytics, superbly. ML often means copying data out. | BI, ML, and AI read the same tables. No copy step. |
| Maintenance | The vendor handles it. You see a bill, not a runbook. | Automated on managed platforms; your job if you roll your own. |
| Lock-in | Storage, compute, and catalog are usually one vendor. | Storage is open; lock-in relocates to the catalog (more on this next). |
| Cost shape | Compute is metered, often with surprises. | Storage is cheap; compute and operations are where the money goes. |
A warehouse is not the dumb choice here. Teams run Snowflake, BigQuery, and Redshift for years and get real work done, and at small scale with pure SQL reporting a warehouse is often the right call. But notice the direction the table leans. The warehouse's edge is turnkey simplicity at the low end. The lakehouse's edge is everything that shows up as you grow: one open copy of your data that more than one engine can touch, ML and AI workloads that would otherwise mean copying the data into yet another system, and storage you actually own. Most teams are walking toward the second column, not the first, which is why "what is a data lakehouse" is a question worth answering well. And notice that the warehouse's one remaining edge in that table is operational: it is turnkey, with no maintenance to run. That edge holds right up until the lakehouse is managed too, at which point it disappears and every other row still favors the lakehouse. If your weakness is the warehouse bill rather than the architecture, start with Best Data Warehouse for Startups instead, because cheaper-warehouse is a different problem than this one.
The real lock-in test (most "open" platforms have a catch)
"Open, no lock-in" is the most repeated and least examined claim in this category. Every vendor says it. Here is the test that actually separates open from open-ish, in three parts:
- Can you copy the files out? Parquet on object storage you control passes trivially. This is table stakes, and most platforms clear it.
- Is the table format interoperable? Iceberg has effectively become the lingua franca, so an Iceberg or Iceberg-compatible table is portable across engines. A format only one engine understands is not.
- Can you leave the catalog? This is the one that catches people. The catalog is the index of which files are which table, and it is quietly becoming the real lock-in point. If an external engine cannot read your catalog, your "open" files are stranded.
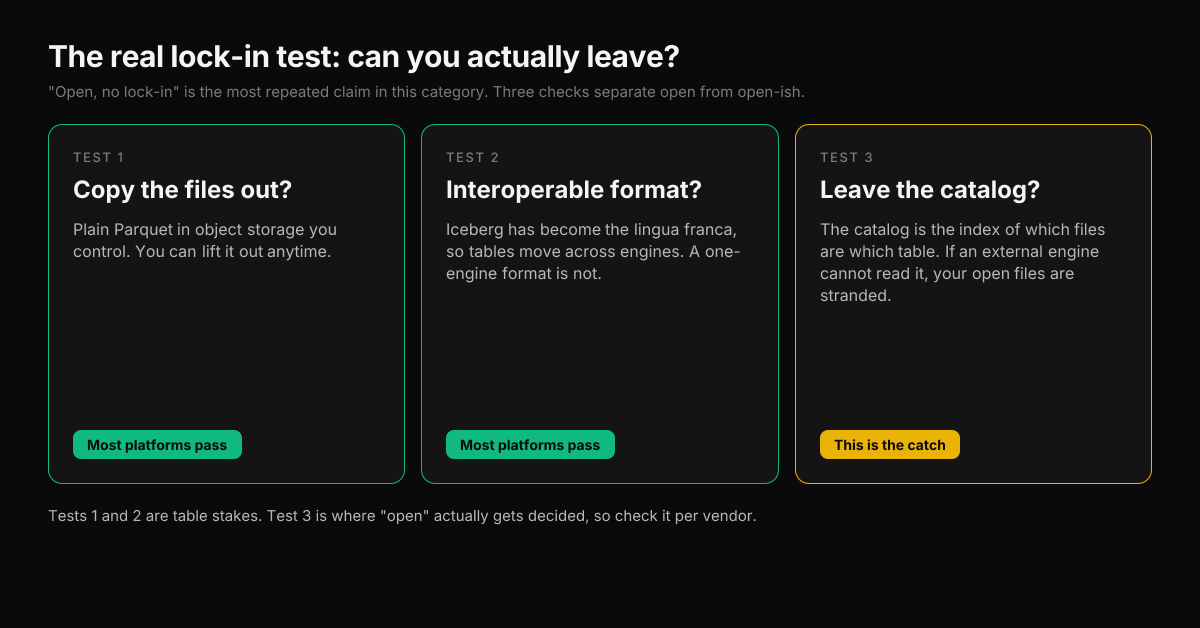
The catch usually lives in part three, and you do not have to take our word for it. Google's own BigQuery documentation warns that "modifying data files for Iceberg managed tables outside of BigQuery can cause query failure or data loss." Read that closely: the files are open Iceberg, but the safe path to write them runs through one engine. The format is portable; the operational leash is the catalog.
To be fair, the gap is closing. Databricks shipped full Apache Iceberg support with native REST catalog APIs in June 2025 and now markets eliminating table-format lock-in directly. Snowflake added external-query-engine access to its Iceberg tables, generally available as of early 2026. The point is not that the big platforms are lying. The point is that "open" is a spectrum, the meaningful test is catalog portability, and you have to check it per vendor instead of trusting the slogan.
And openness usually comes with a premium: the more open and portable your setup, the more of the operating you tend to own. That trade is the one worth designing around. The version we built keeps both sides, and it is fair to run the same three-part test on it. Definite's tables are plain Parquet in object storage you control (copy them out anytime), the format is Iceberg-interoperable so tables move in either direction, and the catalog is a standard SQL database following the open DuckLake spec, with clients beyond DuckDB including Spark and Trino, rather than a closed vendor endpoint. So the catalog you would have to leave is one you can already read directly. The operating is ours, not yours, but the open copy is genuinely yours to walk away with. Some teams will still rationally choose a managed, slightly-more-locked-in warehouse precisely so they never touch a runbook, and that is a legitimate trade. The point is to make it on purpose, with the catalog question on the table.
Why one open copy of your data matters for AI
"AI-native lakehouse" is mostly noise until someone explains the mechanism. Here it is, concretely.
In a proprietary warehouse, every tool that is not the warehouse usually needs its own copy of the data. The notebook gets an export. The vector pipeline gets an export. The new agent framework gets an export. You end up maintaining five copies in five shapes, and they drift.
An open table format breaks that. Because the data sits in open Parquet with an interoperable catalog, many engines read the same tables with no copy: the warehouse query, the Python notebook, the BI tool, and the AI agent all point at one governed copy. Write once, read everywhere, and the replication tax (the ETL pipelines whose only job is shuttling data between systems) mostly disappears. That is the actual reason open formats matter for AI. Not that a table format is magically intelligent, but that you keep a single source of truth that whatever model or agent you adopt in eighteen months can read without a migration. One copy, many engines, including the ones that do not exist yet. It is also why pointing an AI agent at a lakehouse is cheap: it queries the open tables directly instead of burning warehouse credits on every exploratory question.
This is also where a semantic layer earns its place: it is what stops "many engines reading one copy" from turning into "many engines computing revenue five different ways."
Where a warehouse is still the right call
"Better default for most teams" is not "always," and the honest exceptions are worth naming, because a recommendation that only points one way is not a recommendation. A warehouse (or even plain Postgres) is still a fine call if:
- You are under roughly a terabyte of analytical data. Postgres handles analytics surprisingly far, and vendor guidance broadly puts the point where it starts to hurt around the 1 TB mark for analytical workloads. (Treat that number as directional, drawn from vendor field experience rather than a controlled benchmark, but it is the most commonly cited threshold and it roughly matches what we see.) If you have outgrown Postgres specifically, we wrote the signals to watch for.
- A tuned warehouse is keeping up and the bill is fine. If Snowflake or BigQuery is serving your BI cleanly and you are not fighting it, the lakehouse is solving a problem you do not have yet.
- All your workloads are SQL and BI. The lakehouse's edge shows up when ML and AI need the same data the dashboards use. Pure reporting does not stress that seam.
- You insist on rolling your own and have nobody to operate it. A self-run lakehouse that nobody maintains gets slow and expensive fast. The fix here is usually a managed lakehouse rather than the warehouse, but an unmaintained DIY lakehouse is worse than either. Do not run one nobody owns.
And the honest upper bound, because a decision framework that only points one way is not a framework: at very large scale, petabytes and many teams hammering the same tables, the single-catalog, single-engine approach we describe below is the wrong tool, and you want Iceberg with a distributed engine like Spark or Trino. The lakehouse is a wide middle, not a universal answer.
One assumption runs under this entire piece: that you are building on object storage (S3, GCS, or Azure Blob, including your own bucket on a self-hosted setup). If your data has to live somewhere without it, in a fully air-gapped or legacy on-prem environment, the three-layer model here is not your starting point.
A lakehouse where the runbook isn't yours (the bet we made)
This is the part we can speak to first-hand, because it is what we built. The recurring theme above is that a lakehouse is three layers and the middle one comes with a job. The interesting design question is who does that job.
At Definite, the answer is the platform, not the customer. Our storage layer is a lakehouse we brand DuckLake, and its design erases most of the operational pain the middle layer is famous for. The table metadata lives in a SQL (Postgres) catalog instead of thousands of small metadata files scattered across object storage, which is what makes a lakehouse fast to query and simple to operate. The data files are open Parquet. DuckDB is the compute engine, so there is no Spark cluster to run and no distributed system to babysit. And the whole thing is Iceberg-interoperable, so tables can be copied to or from Iceberg in either direction. (To be precise, DuckLake is its own SQL-catalog table format that interoperates with Iceberg, not Iceberg itself. The distinction matters if you are evaluating closely.) Every connected source lands in one set of open tables that your BI, your notebooks, and your AI agents all read from a single copy. Compaction, snapshots, and schema management happen underneath. The customer gets the open copy and the query performance; the runbook is ours. For the longer story of why we made that bet, there is the DuckDB and DuckLake business case.
The practical effect is that running this lakehouse is at least as easy as running a managed warehouse, because you are not the one running it. You connect a source and query it. There is no cluster to size, no compaction job to schedule, no catalog to babysit. And because Definite is also doing the ingestion, the modeling, the semantic layer, and the dashboards, there is arguably less to operate than a standalone warehouse that only handles storage and query and leaves the rest of the stack to you. That is the whole argument in one sentence: a managed lakehouse can be as turnkey as a managed warehouse, which is exactly what removes the warehouse's last advantage.
Two things worth being straight about, since this whole piece is about being straight. First, this is deliberately not "a cheaper Snowflake." The value is that you hold an open, portable lakehouse you could walk away from, not a discounted seat in someone else's proprietary store. Second, it has a scale ceiling. DuckLake with a Postgres catalog and DuckDB compute is built for the wide middle, from roughly a hundred gigabytes to several terabytes, mostly one team. If you are running trillion-row datasets across many teams, that is the Iceberg-plus-Spark world, and you should use it. We would rather tell you where the tool stops than pretend it does not.
You can run that same lakehouse in your own cloud, too. On the self-hosted deployment the Parquet sits in your own S3 or GCS bucket inside your own VPC, which is the literal answer to "can we self-host this on our own infrastructure" and the only reason "data-sovereign" means anything. That tends to be the question the most technical readers ask in the first five minutes.
Frequently asked questions
What is a data lakehouse, in simple terms?
It is a way to store your data as open files in cheap cloud storage while still getting the things a warehouse gives you: real tables, transactions, schema enforcement, and time travel. You get the price and openness of a data lake with the reliability and query behavior of a warehouse, in one place, without copying data between two systems.
Is Snowflake a data lakehouse?
Snowflake started as a data warehouse and has added lakehouse capabilities, most notably support for Apache Iceberg tables and decoupled storage and compute. So as of 2026 it is reasonable to call it a lakehouse platform, but the lineage matters: it is a warehouse that grew toward the lakehouse, which shows up in how its open-table and external-engine support has rolled out over time.
Is Databricks a data lakehouse?
Yes, and it coined the term. Databricks was lakehouse-native from the start, built on object storage with Delta Lake (and now full Iceberg support) and Spark compute. It is the canonical example of the architecture, which is also why most of the public definitions trace back to its 2021 research paper.
Can a data lakehouse replace a data warehouse?
It can be your warehouse, with one condition: something has to run the table maintenance. A managed lakehouse platform replaces a warehouse cleanly because it handles compaction and the catalog for you. A roll-your-own Iceberg-on-S3 setup replaces the warehouse's storage but hands you its operations. Same architecture, very different amount of work, so the answer depends on which version you mean.
Do I need a data lakehouse if I am a 30-person company on Snowflake and dbt?
Probably not yet, and that is a fine place to be. If your warehouse is serving BI cleanly, the bill is reasonable, and you are not yet pushing ML or AI workloads against the same data, a lakehouse is solving a future problem. Revisit it when scale, cost, or AI workloads start straining the warehouse, or when owning an open copy of your data becomes a real requirement rather than a nice-to-have.
The takeaway
A data lakehouse is not one product. It is object storage, an open table format with a catalog, and a query engine, and the middle layer comes with an operational job that someone has to own. Understand it as three layers and most of the marketing fog clears: you can see what you are buying, what you are operating, and where the lock-in actually hides.
The old reason to choose a warehouse over a lakehouse was that the lakehouse was more to run. Take that off the table and the decision is no longer which logo. It is whether you are running the maintenance or someone else is, and whether your data stays open enough to leave. Get those two right and the architecture works for you instead of the other way around.
If you would rather skip the runbook entirely, and get the ingestion, modeling, and dashboards on top of an open lakehouse you own, that is the bet we made at Definite. See how it works.