DuckLake: This is your Data Lake on ACID

How to build an easy (but not petabyte-scale) data lake with DuckLake, DuckDB's open-source Lakehouse extension
Introduction
In modern data architectures, we often face a dilemma: do we choose the flexibility and cost-effectiveness of data lakes, or the reliability, simplicity and performance of data warehouses? What if you could have both?
Enter DuckLake - an open-source Lakehouse extension from DuckDB that brings ACID transactions, time travel, and schema evolution to an easy to setup data lake. In this post, I'll show you how we built a real-time event processing pipeline that demonstrates DuckLake's capabilities.
The Challenge
Imagine you're building an analytics platform that needs to:
- Ingest millions of events per day from your application
- Provide real-time analytics with sub-second query performance
- Allow historical analysis and debugging with time travel
- Maintain data consistency with ACID guarantees
- Keep costs low with efficient storage
Enter DuckLake
DuckLake solves these challenges by combining:
- Parquet files for efficient, open storage
- PostgreSQL for ACID-compliant metadata management
- DuckDB for blazing-fast analytical queries
- Git-like versioning for time travel and auditing
Let's build a production-ready event pipeline to see it in action. All the code for this tutorial is available on GitHub.
Architecture Overview
Our pipeline consists of three main components:
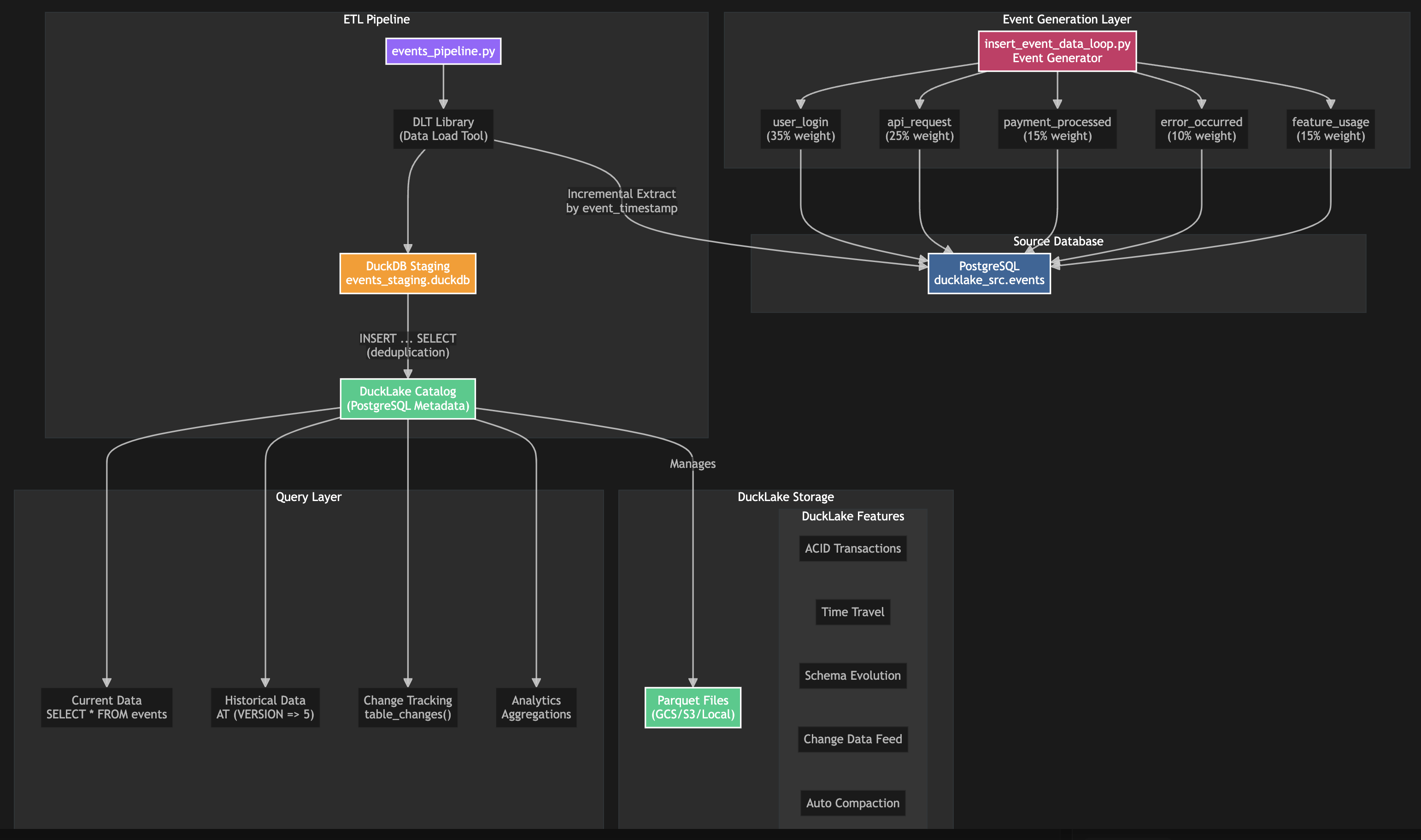
Step 1: Generating Some Data
First, we need a stream of realistic events. Our insert_event_data_loop.py script simulates a production application generating various event types:
EVENT_TYPES = {
"user_login": {
"weight": 35, # Most common event
"details_generator": lambda: {
"user_id": f"user_{random.randint(1000, 9999)}",
"ip_address": f"{random.randint(1, 255)}.{random.randint(0, 255)}.{random.randint(0, 255)}.{random.randint(0, 255)}",
"session_id": str(uuid.uuid4()),
"login_method": random.choice(["password", "oauth_google", "oauth_github", "sso"])
}
},
"api_request": {
"weight": 25,
"details_generator": lambda: {
"endpoint": random.choice(["/api/v1/users", "/api/v1/products", "/api/v1/orders"]),
"method": random.choice(["GET", "POST", "PUT", "DELETE"]),
"status_code": random.choices([200, 201, 400, 404, 500], weights=[50, 10, 10, 15, 5])[0],
"response_time_ms": random.randint(10, 2000)
}
},
# ... more event types
}
The script runs continuously, inserting batches of events with realistic distributions:
# Generate 1000 events every 5 seconds
uv run insert_event_data_loop.py --continuous --rows 1000 --delay 5
Step 2: Incremental ETL with State Management
We built a pipeline in events_pipeline.py, which uses dlt (Data Load Tool) for incremental extraction:
def extract_events_incremental(src_pg_conn: str, staging_db_file: str) -> dict:
"""Extract events table incrementally using DLT."""
# Configure incremental loading on event_timestamp
events_table = sql_table(
credentials=src_pg_conn,
schema="ducklake_src",
table="events",
incremental=dlt.sources.incremental(
"event_timestamp",
initial_value=datetime(2020, 1, 1, tzinfo=timezone.utc)
)
)
# Create pipeline with state persistence
pipeline = dlt.pipeline(
pipeline_name="events_incremental",
destination=dlt.destinations.duckdb(staging_db_file),
dataset_name="staging"
)
# Run the pipeline - only new records are extracted!
info = pipeline.run(events_table, write_disposition="append")
return load_info
The pipeline automatically:
- Tracks state between runs
- Extracts only new records based on
event_timestamp - Handles failures with automatic retries
- Provides metrics on rows processed
Step 3: Promoting to DuckLake
Once staged, we promote events to DuckLake with full ACID guarantees:
def promote_events_to_lake(staging_db_file: str, catalog_conn: str, data_path: str) -> int:
"""Promote staged events to Duck Lake."""
conn = _connect(staging_db_file)
# Attach DuckLake catalog
attach_duck_lake(conn, catalog_conn, data_path)
# Insert new events with deduplication
conn.execute(f"""
INSERT INTO {ducklake_path}.events
SELECT s.* FROM staging.events s
WHERE NOT EXISTS (
SELECT 1 FROM {ducklake_path}.events l
WHERE l.event_id = s.event_id
)
""")
# Transaction automatically committed
# DuckLake creates a new snapshot version
Step 4: Querying with Time Travel
Now the magic happens. With DuckLake, we can query our data at any point in time:
-- Current data
SELECT event_type, COUNT(*) as count
FROM lake.events
WHERE event_timestamp > NOW() - INTERVAL '1 hour'
GROUP BY event_type;
-- Historical data from yesterday
SELECT * FROM lake.events
AT (TIMESTAMP => NOW() - INTERVAL '1 day');
-- Compare versions to see what changed
FROM lake.table_changes('events', 100, 150)
WHERE change_type = 'insert'
AND details->>'severity' = 'critical';
-- Investigate a specific user's journey
SELECT * FROM lake.events AT (VERSION => 42)
WHERE details->>'user_id' = 'user_1234'
ORDER BY event_timestamp;
Performance and Storage Optimization
DuckLake automatically optimizes storage through:
1. Automatic File Compaction
Small files are merged into larger ones for better performance:
CALL ducklake_merge_adjacent_files('lake');
2. Column Statistics
Min/max values and null counts enable efficient query pruning:
-- DuckLake automatically maintains these statistics
-- (metadata tables live in the __ducklake_metadata_<catalog> database)
SELECT * FROM __ducklake_metadata_lake.ducklake_table_column_stats;
3. Partitioning
Organize data by commonly filtered columns:
ALTER TABLE lake.events SET PARTITIONED BY (event_date);
Real-World Use Cases
This architecture is perfect for:
1. Event Sourcing
- Immutable event log with full history
- Replay events to rebuild state
- Debug production issues with time travel
2. Change Data Capture (CDC)
- Track all changes with
table_changes()function - Build incremental data pipelines
- Audit trail with who changed what and when
3. Real-Time Analytics
- Sub-second queries on recent data
- Historical comparisons and trends
- No need for separate OLAP systems
4. Data Science Workflows
- Experiment on historical snapshots
- Reproduce results with version pinning
- Schema evolution for new features
Production Considerations
Monitoring and Maintenance
# Schedule regular maintenance
schedule.every(1).hours.do(lambda: run_events_pipeline())
schedule.every(1).days.do(lambda: expire_old_snapshots())
schedule.every(1).weeks.do(lambda: compact_small_files())
Cost Optimization
- Storage: Parquet compression reduces size by 10-100x
- Compute: Query only what you need with column pruning
- Network: Keep data close to compute (same region)
Scaling Strategies
- Horizontal: Partition by time or business dimension
- Vertical: Use column statistics for selective reads
- Caching: Leverage DuckDB's intelligent caching
Conclusion
DuckLake bridges the gap between data lakes and data warehouses, giving you:
- Flexibility of open formats (Parquet)
- Reliability of ACID transactions
- Performance of columnar analytics
- Simplicity of SQL interfaces
Our event processing pipeline demonstrates how easy it is to build production-ready data infrastructure without vendor lock-in or operational complexity.
Getting Started
Ready to build your own Lakehouse? Here's how:
# Clone the example code
git clone https://github.com/definite-app/ducklake-speedrun
cd ducklake-speedrun
# Install dependencies with uv
uv pip install -r requirements.txt
# Set up your environment
cp .env.example .env
# Edit .env with your connection details
# Start generating events
uv run insert_event_data_loop.py --continuous --rows 1000 --delay 5
# In another terminal, run the pipeline
uv run events_pipeline.py --run --data-path gs://your-bucket/ducklake/
# Query your data with DuckDB
duckdb
> ATTACH 'ducklake:postgres://...' AS lake (DATA_PATH 'gs://your-bucket/ducklake/');
> SELECT * FROM lake.events LIMIT 10;
What's Next?
We're building a data platform at Definite with DuckDB at its core. If you're excited about DuckLake and the possibilities of modern data infrastructure, you might be interested in what we're building. Check out our platform to see how we're making data analytics more accessible.
Resources
- DuckLake GitHub Repository
- DuckDB Documentation
- Example Code from this Post
- DuckDB Performance Benchmarks
Have questions? Reach out on Twitter @thisritchie.