The Best MySQL ETL Tools in 2026: A Decision Framework

You have a MySQL database, leadership wants dashboards, and every request means you're the one querying production at 9 PM. So you search "best MySQL ETL tools" — and most of the top results recommend tools that no longer exist, or haven't gotten a new star on GitHub in years.
Blendo is gone. FlyData got absorbed. Talend Open Studio — the go-to free option — was discontinued in January 2024. Stitch was deprioritized under Qlik. Even Panoply's "Top 9 MySQL ETL Tools" article returns a 404.
The MySQL ETL landscape looks nothing like it did before COVID. ETL (transform before loading) gave way to ELT (load first, transform in the warehouse). Airbyte went from scrappy open-source project to 600+ connectors. AI-powered analytics became a real category.
And the survivors are consolidating fast — Fivetran merged with dbt Labs, then acquired Census and Tobiko Data, racing to become an end-to-end platform.
The right MySQL ETL tool in 2026 depends entirely on who you are and what you're optimizing for. This guide is organized by that — not by alphabet.
| Tool | Type | MySQL CDC | Best For | Pricing |
|---|---|---|---|---|
| Definite | All-in-one platform | Yes (binlog) | One-person data teams wanting insights fast | Free tier; $250/mo Platform tier |
| Fivetran | Managed ELT | Yes (binlog) | Teams with existing warehouses | MAR-based (consumption) |
| Hevo Data | Managed ELT | Yes (binlog) | Startups wanting no-code with a free tier | Free (1M events/mo); paid tiers |
| Airbyte | Open-source / Cloud ELT | Yes (binlog) | DIY teams wanting flexibility | Free (OSS) or credits-based (Cloud) |
| Debezium | Open-source CDC | Yes (binlog) | Engineering teams needing real-time streaming | Free (open source) |
| Apache Spark | Distributed processing | No (JDBC batch) | Large-scale data engineering | Free (open source) |
| AWS Glue | Serverless ETL | No (JDBC batch) | Teams already on AWS | $0.44/DPU-hour (pay-per-use) |
| Skyvia | Web-based ETL | No (poll-based incremental) | Small jobs, freemium users | Free (10K records/mo); paid tiers |
| Matillion | Warehouse-native ELT | Yes | Enterprise data teams | $60K+/year license |
| Integrate.io | Cloud ETL/ELT | Yes (FlyData lineage) | Mid-market, flat-rate pricing | $1,999/mo unlimited |
If You Want Answers Tomorrow, Not Next Quarter
For startups and fast-moving teams, the real cost of MySQL ETL isn't the tool — it's the time, complexity, and engineering burden of assembling a multi-tool pipeline. You need an ETL/ELT tool, a data warehouse, a BI platform, maybe a semantic layer, maybe dbt for transformations — and someone to maintain all of it.
By the time you've stitched that together, you've spent weeks (or months) and thousands of dollars — before answering a single business question.
That's the problem all-in-one platforms solve.
Definite
Definite is an all-in-one data platform that replaces the fragmented stack. Instead of buying Fivetran + Snowflake + Looker + dbt and gluing them together, you get:
- Full SQL and Python access — write queries, build models, and script transformations with the same tools you already know
- 500+ pre-built connectors — including MySQL as a source with CDC via binlog, Stripe, HubSpot, Salesforce, and every other tool your startup runs on
- Built-in managed warehouse — no Snowflake or BigQuery bill to manage, with sub-second queries from megabytes to terabytes
- Governed semantic layer (powered by Cube.dev) — consistent metrics (ARR, churn, NRR) enforced across every report and query
- AI analyst (Fi) — natural language queries against your governed metrics, no SQL required
- Dashboards and reporting — drag-and-drop visualization, Slack alerts, Google Sheets sync
- Open architecture — built on DuckDB, Iceberg/Parquet, and Cube.dev. Export your data and pipeline at any time — no lock-in
Connect your MySQL database and see your first dashboard in under 30 minutes. No infrastructure to maintain. No separate vendors to negotiate. Start with the free tier to test your connectors and data before committing.
The caveat: Definite is newer and less established than Fivetran or Airbyte. Its connector catalog (500+) is broad but verify that your specific sources are covered before committing — particularly niche or custom connectors. And if you need deeply customized multi-step transformations or have an existing warehouse you're committed to, a dedicated ELT tool may be the better fit.
Best for: You if you need insights from MySQL fast, know SQL, and want one platform instead of four — without the infrastructure overhead.
If You Want Managed Pipelines
If you already have a data warehouse (Snowflake, BigQuery, Redshift) and a BI tool, you may just need a reliable way to move data from MySQL to that warehouse. That's where managed ELT platforms come in.
Fivetran
Fivetran is the market leader in managed ELT. Its MySQL connector uses Change Data Capture via binlog replication, reading your binary log instead of querying your production database. Updates stream in near real-time with minimal load on your source, though row-based pricing leads many teams to weigh cost-effective Fivetran alternatives.
- 700+ connectors, fully managed and maintained
- Automatic schema drift handling — Fivetran adapts when your source tables change (though ALTER TABLE operations and ENUM changes trigger full re-syncs)
- Pre-built analytics-ready data models for common sources
- Recently merged with dbt Labs, combining ingestion and transformation under one company
The caveat: Fivetran uses Monthly Active Rows (MAR) pricing — and as of January 2026, deletes count as paid MAR with a $5 minimum per connection. Database connectors like MySQL also carry a base fee on top of MAR charges, so a MySQL source with moderate update volume can easily hit $2,000-3,000/month for Fivetran alone. And Fivetran is just the ingestion layer — you still need a warehouse, a BI tool, and potentially a semantic layer. The full stack cost adds up fast.
Best for: You if you already have a warehouse and budget for consumption-based pricing and want reliable, zero-maintenance data movement at scale.
Hevo Data
Hevo Data is a no-code data pipeline platform with a genuine free tier — 1 million events per month with limited source types. It supports MySQL via binlog-based CDC with near real-time sync.
- 150+ connectors with MySQL CDC support
- No-code pipeline builder — configure in the UI, no SQL or scripting
- Events-based pricing (more predictable than MAR for high-churn tables)
- Four tiers: Free, Starter, Professional, Business — check current pricing
The caveat: The free tier is limited to specific "free sources" — verify that MySQL is available on the free plan before counting on it. Hevo's connector catalog (150+) is significantly smaller than Fivetran (700+) or Airbyte (600+), so check that your other data sources are covered before committing.
Best for: Startups wanting managed MySQL ETL with a genuine free tier to test before committing. Particularly strong if you want no-code setup and events-based pricing.
If You Want Open-Source Flexibility
If you have engineering capacity and want control over your data pipelines — or simply can't justify $2,000/month for a managed tool — open-source options have matured significantly.
Airbyte
Airbyte is the most popular open-source ELT platform. Its MySQL connector supports binlog-based CDC, reading directly from the binary log for near real-time replication. Airbyte reports 3x performance improvements to its MySQL connector, reaching ~11 MB/s throughput.
- 600+ connectors (OSS) / 550+ (Cloud) — the largest open-source connector catalog
- MySQL CDC with incremental snapshots and automatic schema detection
- Self-host for free (Docker or Kubernetes) or use Airbyte Cloud (credits-based)
- Active community and frequent connector updates
Self-hosted trade-off: "Free" means free of license cost, not free of engineering time. You'll need someone to handle deployment, upgrades, monitoring, and scaling. Airbyte Cloud removes that burden but adds usage-based costs. For a comparison of the full-stack economics, see our guide to cost-effective Fivetran alternatives.
Best for: You if you have engineering capacity and want open-source flexibility and the largest connector catalog, with the option to self-host or use a managed cloud.
Debezium
Debezium is an open-source Change Data Capture platform built specifically for database streaming. Its MySQL connector reads the binlog directly for real-time change events — inserts, updates, and deletes streamed as they happen.
- Purpose-built for CDC — not a general ETL tool, but the best at what it does
- Supports MySQL binlog with GTID-based positioning for exactly-once delivery
- Latest stable: v3.4 (January 2026), requires Java 17+
- Traditionally deployed on Kafka Connect, though Debezium Server offers a standalone alternative that sinks to Kinesis, Pub/Sub, Pulsar, Redis, and webhooks — no Kafka required
The caveat: Debezium is a CDC engine, not an end-to-end ETL solution. You get raw change events — what you do with them (load into a warehouse, feed to a stream processor, trigger downstream systems) is your responsibility. Powerful if you need real-time MySQL streaming, but significant engineering required.
Best for: You if you're building a real-time data architecture and need MySQL CDC as a foundation, not a finished pipeline.
Apache Spark
Apache Spark connects to MySQL via JDBC for batch extraction. It's the standard for large-scale distributed processing — but it's designed for data engineering teams, not solo analysts.
- MySQL support via JDBC data source with a dedicated MySQLDialect class
- New in Spark 4.1: Spark Declarative Pipelines (SDP) — a simplified framework for batch and streaming ETL
- Massive scale: designed for terabytes to petabytes
- No CDC support — batch-only extraction from MySQL
The caveat: Spark is infrastructure. You need a cluster (managed via Databricks, EMR, or self-hosted), engineers to write and maintain jobs, and an orchestration layer. It's the right answer for large-scale data engineering — and overkill for getting a MySQL database into a dashboard.
Best for: You if you're processing MySQL data at very large scale alongside other big data workloads.
If You're on AWS
AWS Glue
AWS Glue is a serverless ETL service that connects natively to MySQL via JDBC — particularly strong with Amazon RDS for MySQL and Aurora MySQL. If your MySQL database is already on AWS, Glue eliminates cross-cloud networking complexity.
- Serverless: no clusters to manage, pay only for what you use
- $0.44/DPU-hour standard, or $0.29/DPU-hour with Flex Execution (34% savings for non-urgent jobs with up to 5-minute delayed start)
- Amazon Q integration — describe your ETL pipeline in natural language and Glue generates the code
- Free tier: 1 million Data Catalog objects stored free
- No binlog CDC — batch extraction via JDBC
The caveat: Glue is powerful but AWS-native. If your destination isn't on AWS (loading into Snowflake on Azure, for example), the value proposition weakens. And while serverless eliminates cluster management, the DPU-hour pricing can be hard to predict until you've run a few jobs. Debugging Glue jobs requires comfort with PySpark and the AWS console.
Best for: You if you're already on AWS with MySQL on RDS or Aurora and want serverless, pay-per-use ETL without managing infrastructure.
Niche and Specialized Options
Skyvia
Skyvia is a web-based data integration platform with a freemium model — 10,000 records per month free. It supports MySQL as both a source and destination, but with an important distinction: Skyvia uses poll-based incremental replication via timestamp or autoincrement columns, not true binlog CDC.
That means it works well for small-to-medium datasets with predictable update patterns, but isn't suited for high-volume, high-churn MySQL databases where you need real-time change capture.
Best for: Small data volumes, simple sync jobs, or a quick web-based integration without infrastructure. Not ideal for production-scale MySQL CDC.
Matillion
Matillion is a warehouse-native transformation and integration platform. It supports MySQL as a source and executes transformations directly inside your target warehouse (Snowflake, BigQuery, Redshift, Databricks).
The reality check: Matillion is enterprise software. License fees start at $60,000+/year, and year-one total cost including warehouse compute and implementation can reach $265,000+. For the audience reading this guide — small teams, solo data people — Matillion is likely not the right fit. Including it here for completeness and because you'll see it in other lists.
Best for: Enterprise data teams with warehouse budgets who want ELT with native warehouse execution. Not for startups or small teams.
Integrate.io
Integrate.io is the company that acquired FlyData in 2021, absorbing its MySQL CDC capabilities. It now offers a unified platform spanning ETL, ELT, CDC, and API generation — with a distinctive pricing model: $1,999/month unlimited (flat rate, no per-row or per-connector charges).
That flat-rate model is unusual and can be genuinely cost-effective for teams with high data volumes or many sources. The trade-off is a smaller connector ecosystem and less community momentum compared to Fivetran or Airbyte.
Best for: You if you want predictable flat-rate pricing and need MySQL CDC alongside a broader integration platform.
What could your data tell you?
Enter your domain and we’ll show you the business questions your tools can already answer — you just can’t ask them yet.
Try it with any company domain — no signup required.
What Happened to the Rest?
If you're coming from an older guide, here's the short version of what changed beyond the tools mentioned in the intro:
- Pentaho — Still alive under Hitachi Vantara at version 11. A visual ETL tool with a long pedigree — but it's heavy, on-premises-first, and requires Java expertise. There are lighter options in 2026.
- Domo — Still active but has shifted to opaque consumption-based credit pricing with no public rates. Implementation costs reportedly $15,000-$50,000+. Firmly enterprise-tier.
The Question Nobody Else Is Asking: What Happens After the Data Lands?
Every other MySQL ETL guide stops here — "pick a tool, load your data, done." But if you've ever actually built a MySQL analytics pipeline, you know the ETL tool is the easy part.
Once your MySQL data is in a warehouse, you still need:
- A data warehouse to store it — Snowflake (~$600-1,000/month for a startup workload), BigQuery (variable), or Redshift ($200-500/month for reserved instances)
- A BI/visualization tool to actually see the data — Tableau (~$1,200/month for a small team), Looker ($3,750+/month), Power BI ($10-20/user/month), or open-source Metabase/Superset (free, but you host it)
- A transformation layer — dbt Cloud ($300-400/month for seats and model runs)
- Your time to maintain all of it — keeping pipelines running, schemas updated, dashboards accurate, and fielding ad-hoc requests while you're at it
We ran a few scenarios through our data stack cost calculator to see what the tooling alone costs at different company sizes:
| Company size | ETL + warehouse + BI + dbt |
|---|---|
| 30-person startup (core connectors, Fivetran + Snowflake + Tableau) | ~$2,200/mo |
| 75-person startup (+ CRM and support tools) | ~$2,900/mo |
| 100-person startup (full stack with Looker) | ~$5,900/mo |
Those numbers are just the software. What they don't capture is the hidden cost: the hours you spend configuring connectors, debugging broken syncs, writing transformation logic, and maintaining a warehouse — instead of doing the analysis you were actually hired for.
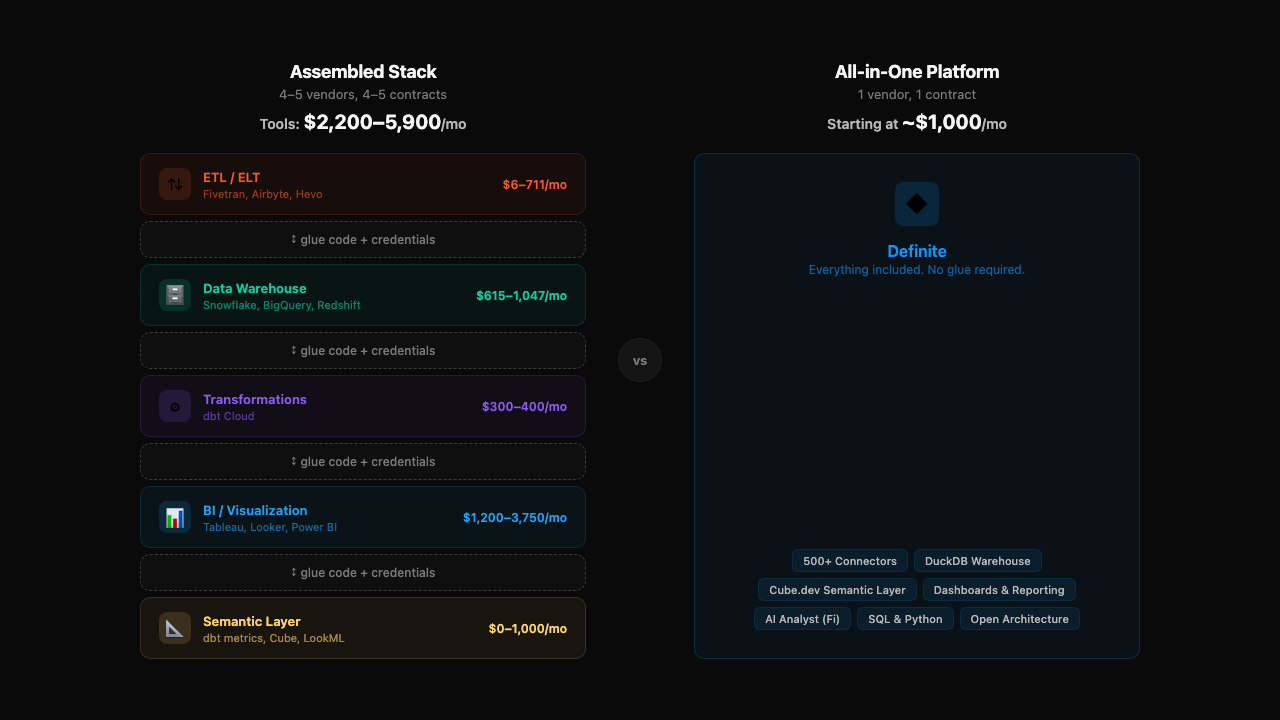
All-in-one platforms take a different approach. Instead of asking you to assemble and maintain four or five tools, they integrate ingestion, storage, and analytics from the start — so you spend your time on insights, not infrastructure.
Try the data stack cost calculator with your own stack to see the full picture.
This isn't a knock on assembled stacks — they're the right answer if you have dedicated data engineering capacity, specific compliance requirements, or deeply customized workflows. But if you're reading a "best MySQL ETL tools" article because you're trying to figure out the simplest path from your MySQL database to answers, the ETL tool might not be the right starting point. The right question might be: do I need to assemble a stack at all?
How to Choose: The Decision Framework
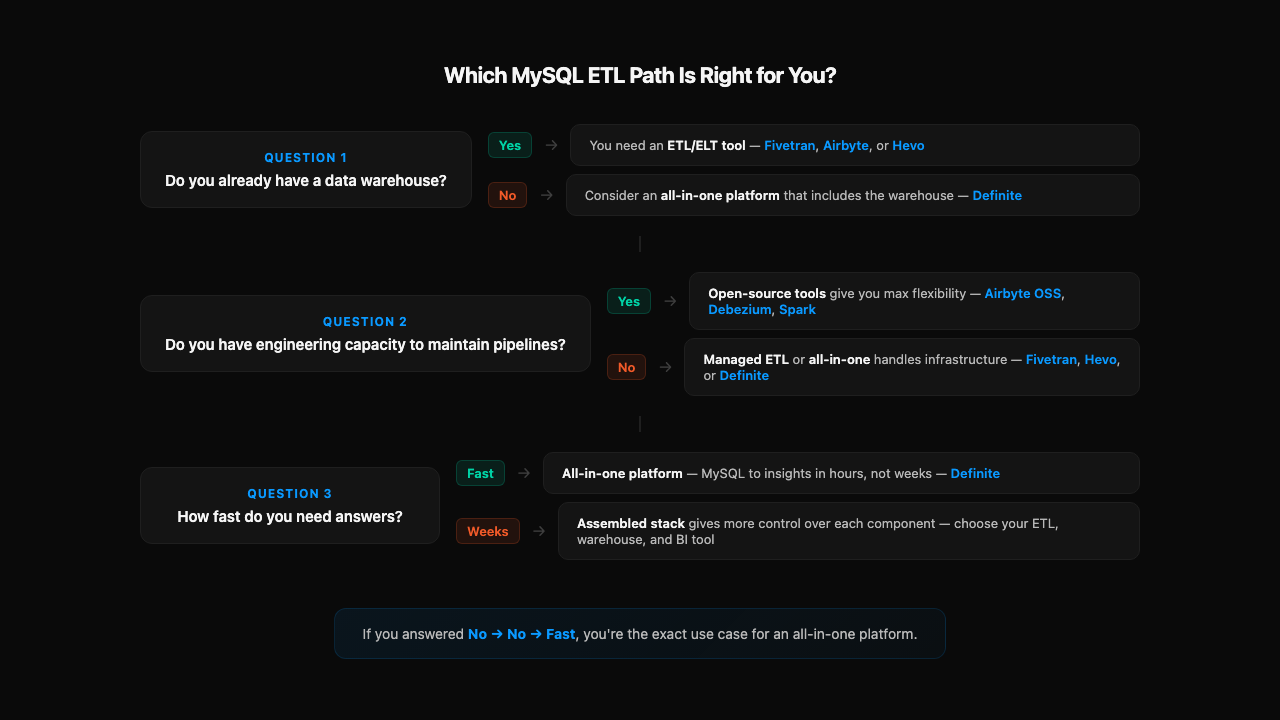
Three questions determine which path is right for you:
1. Do you already have a data warehouse? If yes → you need an ETL/ELT tool (Fivetran, Airbyte, Hevo). If no → consider whether you need one at all, or whether an all-in-one platform (Definite) eliminates that decision.
2. Do you have engineering capacity to maintain pipelines? If yes → open-source tools (Airbyte OSS, Debezium, Spark) give you maximum flexibility and control. If no → managed ETL (Fivetran, Hevo) or an all-in-one platform (Definite) handles the infrastructure for you.
3. How fast do you need answers? If you need answers fast → an all-in-one platform gets you from MySQL to insights in hours. If you have weeks to build → an assembled stack gives you more control over each component.
| Your situation | Best starting point | Time to first insight | Note |
|---|---|---|---|
| Solo data person, need insights fast | Definite | Under 30 min | Includes warehouse + BI — no other tools needed |
| Have a warehouse, want managed pipelines | Fivetran or Hevo Data | Days | ETL only — add warehouse + BI setup time |
| Budget-conscious, willing to self-host | Airbyte OSS | Days to weeks | ETL only — plus deployment and maintenance |
| Engineering team, need real-time CDC | Debezium | Days to weeks | CDC engine only — build the rest yourself |
| On AWS with RDS/Aurora MySQL | AWS Glue | Hours to days | ETL only — within the AWS ecosystem |
| Large-scale distributed processing | Apache Spark | Days to weeks | Processing framework — significant engineering |
Frequently Asked Questions
Do I actually need a separate ETL tool, or can I connect analytics directly to MySQL?
You can — and many small teams start by connecting a BI tool like Metabase directly to their MySQL production database. It works until it doesn't: analytical queries compete with your application for resources, you have no historical snapshots, and a heavy dashboard can slow down your product for real users. If your MySQL database is small and your queries are light, direct connections are a valid starting point. Once you outgrow that, you need either an ETL tool loading into a separate warehouse, or an all-in-one platform that handles ingestion and analytics together.
What's the difference between CDC and batch ETL for MySQL — and which do I need?
Batch ETL runs on a schedule (hourly, daily) and pulls all records matching a filter — typically using a timestamp column like updated_at. It's simpler to set up but misses deletes and can miss records that change between runs. CDC (Change Data Capture) reads MySQL's binary log (binlog) to capture every insert, update, and delete in real time. It's more accurate, lower-latency, and puts less load on your production database — but requires binlog to be enabled (binlog_format=ROW) and appropriate MySQL permissions. If you're on a managed instance like RDS or Aurora, enabling binlog is usually a parameter group change. For most production MySQL ETL, CDC is worth the setup.
What's the cheapest way to move MySQL data into analytics when I don't have a data team?
The cheapest tool is free open-source Airbyte (self-hosted) — but "free" requires Docker/Kubernetes knowledge and ongoing maintenance time. The cheapest path to answers depends on what you value. If you value your time, Definite's free tier lets you test your MySQL connection and connectors before committing, and Hevo Data offers 1M events/month free. If you value cost over time, Airbyte OSS + DuckDB + Metabase is a genuinely capable free stack — but expect to spend a few days setting it up and a few days each month maintaining it.
I'm the only data person. Which approach saves me the most time?
An all-in-one platform. Assembling ETL + warehouse + BI means you're maintaining three vendors, three sets of credentials, three failure points, and three upgrade cycles. When something breaks at 2 AM, you're debugging the connection between tools, not analyzing data. A platform that handles ingestion, storage, and visualization in one place means one thing to learn, one thing to maintain, and one support team to call.
Can I use these tools if my MySQL database is on RDS or a managed service?
Yes — every tool in this guide works with managed MySQL instances (Amazon RDS, Aurora MySQL, Google Cloud SQL, Azure Database for MySQL, PlanetScale). For CDC-based tools (Fivetran, Airbyte, Hevo, Debezium, Definite), you'll need to enable binary logging on your managed instance. On RDS, this means setting binlog_format=ROW in your parameter group and ensuring the tool's user has REPLICATION SLAVE and REPLICATION CLIENT privileges. Most managed MySQL services support this — check your provider's documentation for the specific parameter group or configuration flag.
How do I handle schema changes in MySQL — will they break my pipeline?
This varies significantly by tool. Fivetran handles most schema drift automatically but triggers a full table re-sync on ALTER TABLE operations and ENUM column changes — which can spike your MAR costs. Airbyte detects new columns automatically in CDC mode and adds them to the destination. Debezium captures schema changes as events but your downstream consumers need to handle them. Definite detects schema changes automatically during sync. The safest approach: test schema changes in a staging environment first, and check your tool's documentation for how it handles the specific change you're making (column adds are usually fine; column renames and type changes are where things get tricky).
Get Started
The right question isn't which ETL tool is best — it's whether you need to assemble a stack in the first place.
If you want to try the all-in-one approach, Definite connects your MySQL database and gets you from raw data to governed metrics in under 30 minutes — no warehouse, BI tool, or data engineer required.
If you want to compare the assembled stack options, our guide to cost-effective Fivetran alternatives covers the economics and trade-offs in detail.