How to Build a Data Foundation at Series A Without Hiring a Data Engineer

You just got handed "the data problem."
Maybe you're four days into a RevOps role at a Series A startup. Maybe you've been here six months and the CEO finally said the words: "We need to get our data in order." Either way, you're the person who has to figure this out — and you're not a data engineer.
This guide is for you. Not for the data engineer setting up their ideal stack. Not for the CTO who wants to architect a data platform. For the ops person, the RevOps lead, the first analytics hire who needs to stand up data infrastructure alone — with budget available but no headcount to burn.
Here's what you need to know:
- At Series A, "data infrastructure" means four things: pull your data together, store it, query it, and give your CEO dashboards. That's it.
- The real constraint isn't money — it's that every tool you add is a tool you maintain alone.
- You have three realistic paths: the full modern data stack (~$1,200–3,100/mo in tools, 2–6 weeks), a consolidated data platform ($250/mo, days), or a minimal bridge that buys you time.
- The architectural decisions that actually matter for future-proofing are simpler than you think — and they're not about which warehouse you pick.
The gap feels enormous. It isn't.
Maybe you've worked somewhere data-mature — a company where dashboards were trusted and leadership never had to ask for a report. You know exactly what you're missing. But you're comparing your Series A startup to a company that had a data team of five. You don't need what they had. You need the version of it that one person can stand up and that your CEO can use this quarter.
What "data infrastructure" actually means at Series A
Strip away the enterprise framing. At a 20–50 person company, you need exactly four capabilities:
- A way to pull data from your tools — your CRM, payment system, product database, ad platforms. This is the "connectors" or "ETL" layer.
- A place to store and model it — somewhere the data from different sources lives together in a queryable format.
- A way to ask questions — SQL access, a query interface, or an AI assistant that can generate answers.
- Dashboards leadership can check without asking you — self-serve reporting that doesn't require you to pull a CSV every Monday morning (the interface only works if the warehouse and metrics layer exist).
That's it. You don't need a data mesh. You don't need a lakehouse architecture. You don't need dbt orchestration. You don't need a reverse ETL pipeline. All of those are real things that solve real problems — at a later stage, with more people.
Right now, your job is to close the loop from raw data to business answers. Everything else is premature optimization.
The real constraint isn't budget — it's headcount
This is the part most "startup data stack" guides get wrong. They focus on tool costs and skip the part that actually matters: who maintains all of it.
At Series A, you probably have money. The funding is there. What you don't have is a second person to maintain infrastructure. And the traditional data stack — Fivetran for ingestion, Snowflake or Redshift for storage, dbt for transformations, Looker or Metabase for dashboards — requires exactly that: someone whose job is keeping the pipes running.
The math is stark. For a 50-person company with 4 data sources, the tools run $1,200–3,100/mo. But the real cost is people: $3,500–4,000/mo to keep those tools running, even at a quarter of one person's time. People costs exceed tool costs by 3x from day one.
That means the question isn't "which tools can we afford?" It's "which path lets one person deliver answers without becoming a full-time infrastructure maintainer?"
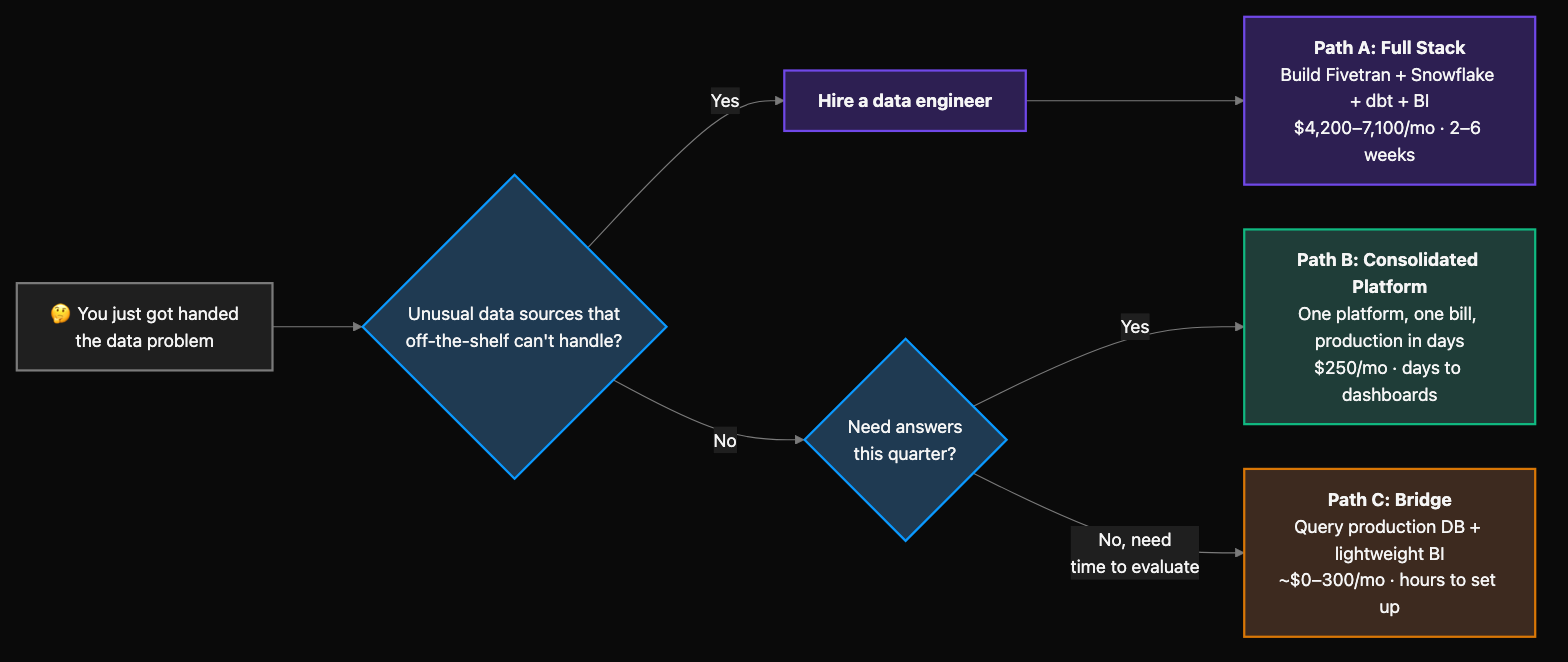
Three paths to a data foundation (with real costs)
There are exactly three ways to stand up data infrastructure at Series A. Each has a cost, a timeline, and a maintenance burden. Here's what they actually look like for one person.
Path A: The full modern data stack
What it is: Assemble the best-of-breed tools yourself — an ETL tool (Fivetran, Airbyte), a cloud warehouse (Snowflake, Redshift, BigQuery), a transformation layer (dbt), and a BI tool (Looker, Metabase, Tableau).
What it costs:
| Component | Tool examples | Monthly cost |
|---|---|---|
| ETL / ingestion | Fivetran, Airbyte | $120–500 |
| Cloud warehouse | Snowflake, Redshift | $300–700 |
| Transformations | dbt Cloud | $300–500 |
| BI / dashboards | Looker, Metabase, Tableau | $0–1,400 |
| Tools subtotal | $720–3,100 | |
| Your time (0.25 FTE) | $3,500–4,000 | |
| Total | $4,200–7,100/mo |
Ranges based on 2025–26 pricing for a 50-person company with 4 data sources. See our data stack cost guide for detailed breakdowns.
Setup timeline: 2–6 weeks to a production dashboard. On the fast end, that's someone who's done this before with well-documented data sources. On the slow end — which is more common — you're debugging connector configurations, learning dbt syntax, figuring out Snowflake IAM roles, and getting burned by Fivetran's connector-level billing changes.
Maintenance burden: 5–10 hours/week initially — monitoring connector syncs, fixing broken pipelines, updating dbt models when source schemas change. This grows to 15–20 hours/week as you add sources and complexity. At that point, you're spending half your time on infrastructure instead of answering business questions.
When it makes sense: You're planning to hire a data engineer in the next 6 months and want to pre-build the stack they'd build. Or your data sources are unusual enough that off-the-shelf platforms can't handle them. Be honest about whether this is your situation — most Series A companies aren't there yet.
Path B: A consolidated data platform
What it is: One platform that handles the full pipeline from raw data to governed answers — connectors, storage, transformation, analytics, and dashboards in a single product. Instead of assembling four tools and maintaining the seams between them, you use one.
Definite is an example of this approach: connectors for HubSpot, Stripe, Salesforce, Postgres, and 500+ other sources, with a built-in data lake, semantic layer, full SQL access, and an AI assistant. You write SQL when you need to and drag-and-drop when you don't. Your data is stored in open formats (DuckDB/Parquet) — if you ever leave, you take it with you.
What it costs: You're replacing 3–4 vendor contracts and their coordination tax with a single platform and a single bill. Definite's Standard plan is $250/mo with unlimited connectors and users, on a credit-based model that scales with usage. Your time investment is lighter — maybe 2–5 hours/week on metric definitions and dashboards instead of 5–10 on infrastructure.
Setup timeline: Minutes to connect your first data source. Days — not weeks — to production dashboards. You can get started in under 30 minutes and have real dashboards running within the first week.
Maintenance burden: Low. No pipeline orchestration to manage, no warehouse to tune, no connector monitoring scripts to write. The platform handles ingestion and storage; you focus on defining metrics and building dashboards.
The catch: You're choosing a single vendor for your entire data layer. If Definite's roadmap diverges from your needs, switching costs are real — even with portable data formats. You also get less customization than a DIY stack: you can't swap in a different transformation framework or wire up a custom orchestration layer. And if you eventually hire 3+ data engineers who want full control over every layer, you'll likely outgrow a consolidated platform and migrate to a stack they build themselves.
When it makes sense: You're the only data person and need answers this quarter. You want your CEO to have self-serve dashboards without assembling a four-tool stack. You'd rather spend your time on analysis than on infrastructure maintenance.
Path C: Buy yourself time with a minimal setup
What it is: Query your production database directly with a lightweight BI tool, or export CSVs into Google Sheets. No warehouse, no ETL, no transformation layer.
What it costs: Nearly free for the tools. The cost is hidden: performance risk and manual labor.
Setup timeline: Hours. Connect Metabase or a similar tool to your production Postgres and start building queries.
Maintenance burden: Depends on your tolerance for manual work. You'll be exporting data, refreshing spreadsheets, and answering "can you pull the latest numbers?" requests on a daily basis. There's no single source of truth — everyone has their own version of the data.
The catch: Your production database can't handle analytics queries alongside application traffic. Heavy queries slow down your product for actual users. A read replica ($100–300/mo) solves the performance problem but adds another thing to maintain. And none of this creates institutional memory — when you leave or get busy, the reporting stops.
When it makes sense: You need 90 days to evaluate properly and the CEO just needs basic dashboards now. This is a bridge, not a destination. Treat it that way.
The comparison (screenshot this for your CEO)
| Path A: Full Stack | Path B: Consolidated Platform | Path C: Minimal/Bridge | |
|---|---|---|---|
| Setup time | 2–6 weeks | Days | Hours |
| Your time/week | 5–10+ hrs on infrastructure | 2–5 hrs on metrics and dashboards | Ongoing manual pulls |
| Tool cost | $720–3,100/mo | $250/mo | ~$0–300 |
| Total cost | $4,200–7,100/mo incl. your time | ~$1,500–3,000/mo incl. your time | ~$0–300 (+ your Monday mornings) |
| What you can do | Everything, eventually | Full analytics + dashboards + AI + SQL | Basic queries and reports |
| What breaks | Pipelines, at 2am, when you're the only one on call | Vendor dependency; less customizable than DIY | Performance, scale, governance |
| Best for | Teams hiring a data engineer soon | One person who needs answers now | Buying time while you evaluate |
What a future data engineer will actually care about (and what they won't)
Here's the anxiety nobody talks about: you're making infrastructure decisions that feel like they should belong to someone with a data engineering title. And you're worried that when you eventually hire that person, they'll look at what you built and tear it down.
Some of that fear is valid. Most of it isn't.
What actually matters to your future data engineer:
- Clean metric definitions. If "revenue" means the same thing everywhere in your system — in dashboards, reports, and ad hoc queries — your future hire will thank you. If every team has their own definition in their own spreadsheet, that's the first thing they'll have to fix. A semantic layer or governed metrics model solves this from day one.
- Accessible, queryable data. Data that lives in a format they can read, query, and build on. Not locked in proprietary exports or scattered across Google Sheets.
- Documentation of what connects where. Even a simple diagram of "HubSpot syncs to X, Stripe syncs to X, production DB syncs to X" saves them weeks of archaeology.
What matters less than you think:
- Which warehouse you picked. Your future hire may prefer Snowflake over BigQuery or vice versa, but metric definitions matter more than storage engines. Most companies rebuild their stack every 2–3 years anyway — the tooling layer is expected to evolve.
- Whether you used dbt. If you're the only person writing SQL, dbt Cloud adds cost and complexity you don't need yet. Your future hire will introduce a transformation layer when the team grows and multiple people need to collaborate on data models. That's the right time — not now.
- Your dashboard layouts. These get rebuilt constantly. Nobody inherits dashboards; they inherit data models and metric definitions.
The bottom line: if your data is clean, your metrics are defined, and your sources are connected, a future data engineer will build on your foundation — even if they swap out the tools underneath.
Your first two weeks: what to do (and what to skip)
Whichever path you choose, here's what your first two weeks should look like.
Week 1: Close the loop from data to one answer
- Connect your 3–4 core data sources (CRM, payment system, product database, marketing platform)
- Define your top 5 business metrics — the numbers your CEO asks about in every meeting (MRR, pipeline, conversion rate, churn, CAC). If you're fundraising, see our guide to investor-ready reporting for the full metric framework investors expect.
- Build one dashboard your CEO will actually check. Not a perfect dashboard — a useful one. If they open it on Monday morning instead of asking you to pull numbers, you've won.
Week 2: Expand the foundation
- Add your next tier of data sources (support tools, ad platforms, product analytics)
- Build views for each team that needs them — sales pipeline for the CRO, marketing attribution for the growth lead, financial reporting for the CFO
- Set up automated refreshes so dashboards stay current without you manually triggering syncs
What to skip (for now):
- Data modeling perfection. Your models will evolve. Get the basic definitions right and iterate. Don't spend three weeks designing a star schema nobody else will query.
- Complex transformation pipelines. If a SQL view solves the problem, use a SQL view. Introduce orchestration when you have more than one person writing transformations.
- Governance frameworks. Access controls and audit trails matter at scale. At Series A with 5 people looking at data, they're overhead. But do define your core metrics consistently from the start — that's not governance, it's sanity.
FAQ
Do I actually need a data warehouse if I only have HubSpot, Stripe, and Postgres?
Not necessarily. If your question volume is low and you don't need complex cross-source joins, a consolidated platform (Path B) gives you warehouse-grade query capabilities without a separate warehouse. Definite, for example, uses DuckDB internally — you get sub-second query performance without ever thinking about warehouse configuration. If your data volume is small and queries are simple, even Path C works for a while. The warehouse becomes necessary when you need to join data from 5+ sources, run heavy analytical queries, or support multiple concurrent users.
Is dbt overkill if I'm the only person writing SQL?
At this stage, probably yes — at least dbt Cloud, which runs $300+/mo. dbt Core is free and some solo practitioners use it effectively, but it adds complexity: you're maintaining a DAG, scheduling runs, and writing tests on top of writing the actual SQL. The value of dbt is collaboration — versioned models, documentation, and testing for a team. When you're the only one writing queries, SQL views get you 80% of the value at 10% of the complexity. Introduce dbt when you hire someone who'll collaborate on the data models. See our startup data stack guide for more on when each tool earns its place.
What's the real monthly cost of the full modern data stack?
For a 50-person company with 4 data sources: $1,200–3,100/mo in tools, plus $3,500–4,000/mo in fractional people time (assuming 0.25 FTE). Total: $4,200–7,100/mo. The people cost is the number most tool-comparison guides leave out. See our complete cost guide for stage-by-stage breakdowns.
Will we have to migrate everything when we hire a data engineer?
Not if you get the foundation right. Your future data engineer will keep your metric definitions, data models, and source connections — that's what takes the most time to build. They may want to swap out the tooling layer (different warehouse, different BI tool), and that's fine. That's a week of work for an experienced data engineer, not a rebuild. What they can't recover is months of ad hoc definitions scattered across spreadsheets with no documentation. The foundation is the metrics, not the tools.
Make the call
If you're reading this at 11pm trying to figure out what to tell your CEO tomorrow, here's the decision framework one more time:
- Hiring a data engineer in the next 6 months? Path A. Build the stack they'd build.
- You're the only data person and need answers this quarter? Path B. One platform, production dashboards in a week, and a foundation that holds.
- Need 90 days to think? Path C. Bridge with a lightweight BI tool, but document everything — you'll thank yourself later.
Screenshot the comparison table. Pair it with your recommendation and a one-paragraph justification: "Based on our team size, budget, and timeline, I recommend [Path X] because [reason]. Here's what we'll have in two weeks, and here's when we'd revisit this decision." Your CEO doesn't need to understand warehouse architecture. They need the cost, the timeline, and what they'll see on their dashboard next month.
Model your current stack costs → — see what teams your size typically pay across ETL, warehouse, BI, and people.
If you want to see what Path B looks like in practice: try Definite free.