Conversational Analytics Is Solved. Just Not at the Interface.

The demo is always the same. Someone types "what was revenue last month?" into a chat box, a chart appears in four seconds, and the room nods. Then you connect the same tool to your actual warehouse, the one with fifteen years of accumulated schema, four columns that could plausibly mean "revenue," and a transactions table nobody fully trusts — and it picks the wrong one. Confidently. With a tidy summary paragraph explaining a number that's off by 30%.
If you've lived this, you're in good company. You've probably seen Redditors asking the question plainly: "Is conversational analytics actually a solved problem?", with a qualifier that says a lot: "I don't think Big Tech has it figured out." It's a fair question, and we're not a neutral party to it: we build a data platform with an AI analyst on top, and we watch that analyst succeed and fail against real customer warehouses every week. So take our answer with that disclosure attached — and check the receipts as you go, because everything load-bearing below is sourced to public benchmarks and other vendors' own documentation, not our opinion of ourselves.
The answer: yes, it's solved — just not where everyone keeps trying to solve it. The failures you've seen aren't LLM failures. They're foundation failures, and teams that solve the foundation — governed definitions, with an agent that works the entire stack instead of just the chat box — are running trustworthy conversational analytics in production today. That's not industry commentary; it's the specific engineering lesson this category keeps learning, most recently published by Anthropic about its own warehouse. The distinction changes what you should do next.
The short version:
- Conversational analytics (the BI sense: asking questions of your business data in plain language — not the contact-center kind that mines support transcripts) is a solved problem — but it's solved at the foundation, not the interface, which is why interface-first deployments keep failing in production.
- The wrong answers trace to the data underneath: ambiguous metric definitions, undeclared join logic, and schemas too large and messy for any model to interpret unaided.
- The benchmark record and the vendors' own documentation both point to the same conclusion: accuracy comes from a governed semantic layer, not a smarter model. Anthropic's own data team measured it: under 21% accuracy pointing Claude at the raw warehouse, over 95% with a governed semantic stack around it.
- The fix is smaller than it sounds. You don't need to model every table — you need governed definitions for the couple dozen metrics leadership actually asks about. And the definitions no longer have to be hand-written: AI agents can now draft them; your job is to sign off on the decisions.
The question nobody answers with a mechanism
Vendors say it works: ask anything, no SQL required. Practitioners say it lied to them. Both are right about their evidence, and almost nobody on either side argues the cause. That's the gap this post exists to fill — and we can fill it because the four failure mechanisms below aren't ones we read about. They're ones we've had to engineer around.
This promise also predates the technology that's supposed to deliver it. In 2019 — before anyone had typed a prompt into ChatGPT — Gartner predicted that by 2020, half of all analytical queries would be generated via search, NLP, or voice. That didn't happen. The interface kept improving and the prediction kept missing, which should make you suspicious of any explanation that centers on the interface. Users feel the difference, too — in a 2025 BARC survey, 85% of data leaders said they trust their BI dashboards while only 58% trust AI/ML outputs. Same data, same people. One runs on definitions someone governed; the other guesses.
Why the demo lies: four failure mechanisms
The demo schema is clean, small, and unambiguous. Yours isn't. Here's what actually goes wrong when the schema gets real — the pathology behind the "confidently wrong" answer, drawn from watching an AI analyst work against production warehouses, not from a survey of the literature.
1. Four columns named revenue
Your warehouse has orders.total_amount, payments.captured_amount, invoices.amount_due, and a revenue column in a table an analyst built in 2023 and nobody documented. A human analyst knows which one finance considers canonical — because they asked, once, and remembered. A model connected to raw tables has no way to know. Which revenue is revenue is not discoverable from the schema. It's a decision, and if nobody recorded the decision, the model picks the most plausible-looking candidate and commits.
2. The join that silently multiplies
Ask "what was revenue last month?" against raw tables and a model has to infer the join path. A common failure looks like this:
-- What the model wrote: plausible, wrong
SELECT SUM(o.total_amount)
FROM orders o
JOIN order_items oi ON oi.order_id = o.id
WHERE o.created_at >= '2026-05-01' AND o.created_at < '2026-06-01';
Joining orders to line items before summing the order total counts each order once per item — a three-item order triples its revenue. The query runs, returns a believable number, and fans out silently. And here's how easy this trap is to fall into: the obvious "fix" — join refunds directly and subtract — has the same bug, because an order with two partial refunds duplicates the order row. The version finance actually means has to aggregate refunds before they ever touch the join:
-- What finance actually means
SELECT SUM(o.total_amount) - COALESCE(SUM(r.refunded), 0)
FROM orders o
LEFT JOIN (
SELECT order_id, SUM(amount) AS refunded
FROM refunds
GROUP BY order_id
) r ON r.order_id = o.id
WHERE o.created_at >= '2026-05-01' AND o.created_at < '2026-06-01'
AND o.is_test = false;
Nothing about the wrong query is unintelligent. It's a reasonable guess in the absence of declared join logic — which is exactly the problem. We've written before about what it takes to get LLM-to-SQL output you can trust; the short version is that "reasonable guess" is not a property you want in a revenue number.
3. Definitions that live in people's heads
Databricks put it plainly in a piece on conversational BI: "You ask three executives at the same company to define profit. You will get three different answers." Gross or net? Including trial conversions? Recognized or booked? Every company runs on metric definitions that exist as institutional memory, not as code. An AI querying raw tables doesn't just lack those definitions — it has no way to know they exist. It will answer the question as asked, which is rarely the question that was meant.
4. Real schemas are too big to interpret unaided
The Spider 2.0 benchmark — built from real enterprise data workflows rather than tutorial databases — uses warehouses that often exceed 1,000 columns, some past 3,000. At that scale the problem isn't whether the schema fits in a context window (windows are enormous now); it's signal-to-noise. Hundreds of plausible candidate tables, near-duplicate columns, stale copies. NLQ tools manage this by quietly subsetting: Wren AI's own tuning docs default to retrieving the top 10 tables per question, because indexing wide schemas breaks model token limits. We've talked with a solo analyst who watched an NLQ tool fall over on his 250-table production database — the tool wasn't broken, it just was never going to read 250 ungoverned tables and guess right.
Notice what these four mechanisms have in common: not one of them is fixed by a better model. Each one is missing information, not missing intelligence.
The model was never the bottleneck
The benchmark record makes this unusually concrete.
When the Spider 2.0 paper was published in November 2024, it reported that GPT-4o — scoring 86.6% on the older, cleaner Spider 1.0 benchmark — succeeded on just 10.1% of Spider 2.0's real-world tasks. Same model. The only thing that changed was that the schemas got real.
Since then the Spider 2.0 leaderboard has climbed dramatically — top entries now report scores in the 65–96% range depending on track (self-reported, worth noting). But look at what climbed: every top entry is an agentic system, not a bare model. They win by doing schema exploration, metadata retrieval, and context engineering before writing SQL — in other words, by manufacturing a foundation for every question, at inference time, with compute. The leaderboard's own history is the argument: the variable that moved accuracy was never the model. It was how much curated context the system brought to the schema.
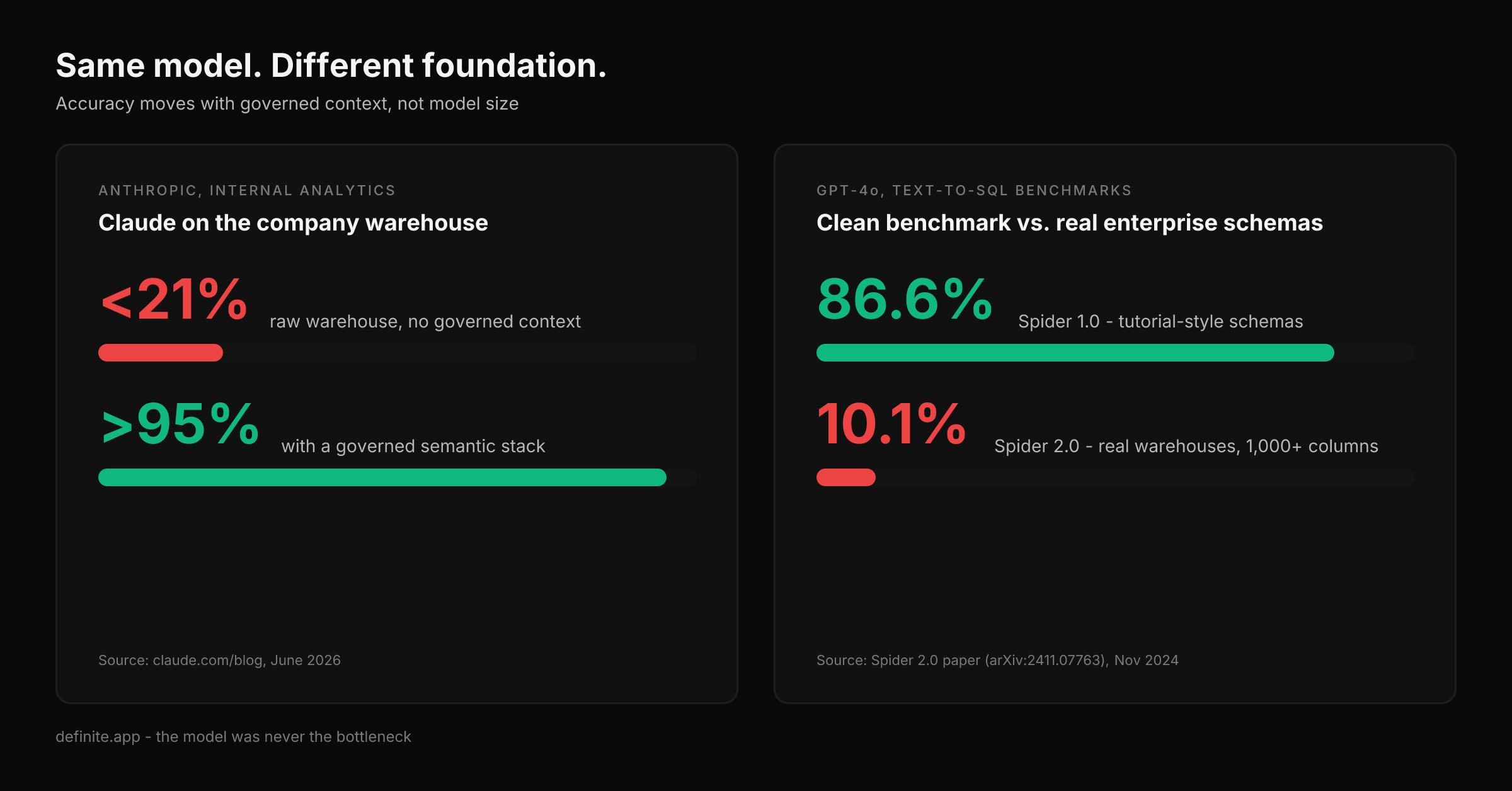
Then there's the datapoint that should end the argument, because of who published it. Anthropic's data team — the company whose entire business is making the model better — wrote up how they automated 95% of their internal business analytics queries with Claude. Pointed at the warehouse without governed context, Claude answered correctly less than 21% of the time. With the stack they built around it — data foundations, a semantic layer and sources of truth, and procedural knowledge for using them — accuracy exceeds 95%, approaching 99% in some domains. Same models. Their own diagnosis, in their own words: the central problem is mapping a user's question "to specific and up-to-date entities in our data model" — and once that works, "the resulting execution and SQL becomes trivial." If a smarter model were the fix, the model company would have been the first to find out.
BIRD, the other major real-world text-to-SQL benchmark, shows the same shape from a different angle: human data engineers score 92.96%, and after three years of submissions, the best systems plateau around 82% — with curated knowledge evidence supplied. Two honest conclusions follow. First, the gap between demo and production is a foundation gap. Second — and this separates an honest argument from a vendor page — some failures really are model failures. Dialect quirks, aggregation logic, instruction slips. A governed foundation fixes the largest class of failures, not all of them. Anyone who tells you their AI analyst is always right is running the same play that burned you last time.
Why agents can't just rediscover the context every time
If inference-time scaffolding can manufacture context per-question, why not just do that instead of governing anything? Because exploration can discover what your schema contains, but not what your company means. An agent can find all four revenue columns; it cannot find out which one is canonical, because that fact doesn't live in the database. It lives in a decision someone made in a meeting. Per-question rediscovery is also expensive, slow, and unauditable — you get a different exploration path each time, which is exactly the "second source of truth" problem that makes solo data people distrust these tools in the first place. A governed semantic layer is the durable version of what those leaderboard agents keep rebuilding: the context discovered once, ratified by a human, written down, and reused by every question after.
Every vendor that made it work says the same quiet thing
We're not the only ones who learned this in production. Read the documentation of everyone who ships conversational analytics, and a pattern emerges that none of them puts in the headline.
Google's Looker docs state that conversational analytics is "grounded in the Looker semantic modeling layer" for "governed, trusted self-service BI" — and the rollout guide concedes the contrapositive: if the semantic model isn't properly constructed, responses "could be inaccurate." The standard Gemini disclaimer — output "can generate output that seems plausible but is factually incorrect" — still applies even with grounding.
ThoughtSpot's page on conversational analytics admits models "can also 'hallucinate'" and names the fix in one sentence: "A governed semantic layer solves this by standardizing business language, so everyone gets the same, accurate answer." They didn't leave it as a paragraph — they shipped a semantic-layer product to do it.
Databricks says it surveyed more than 20,000 customers and found "the single biggest barrier to AI and data adoption was a lack of trust" — and its answer, too, runs through governed, certified definitions.
If you need one paragraph to forward to the executive who just sent you a demo video, make it this one:
The demos aren't lying — but they're demoing the model, not the foundation. Every vendor that has made conversational analytics work in production says the same quiet thing in their docs: the AI is only as accurate as the governed definitions it queries. The demo works because the demo schema has those definitions built in. Our data doesn't, yet. That's the gap — and it's fixable: a couple dozen metric definitions, not a re-platforming project.
That's not an excuse for slowing down the AI initiative. It's the prerequisite list for making it real.
What a governed semantic layer actually has to contain
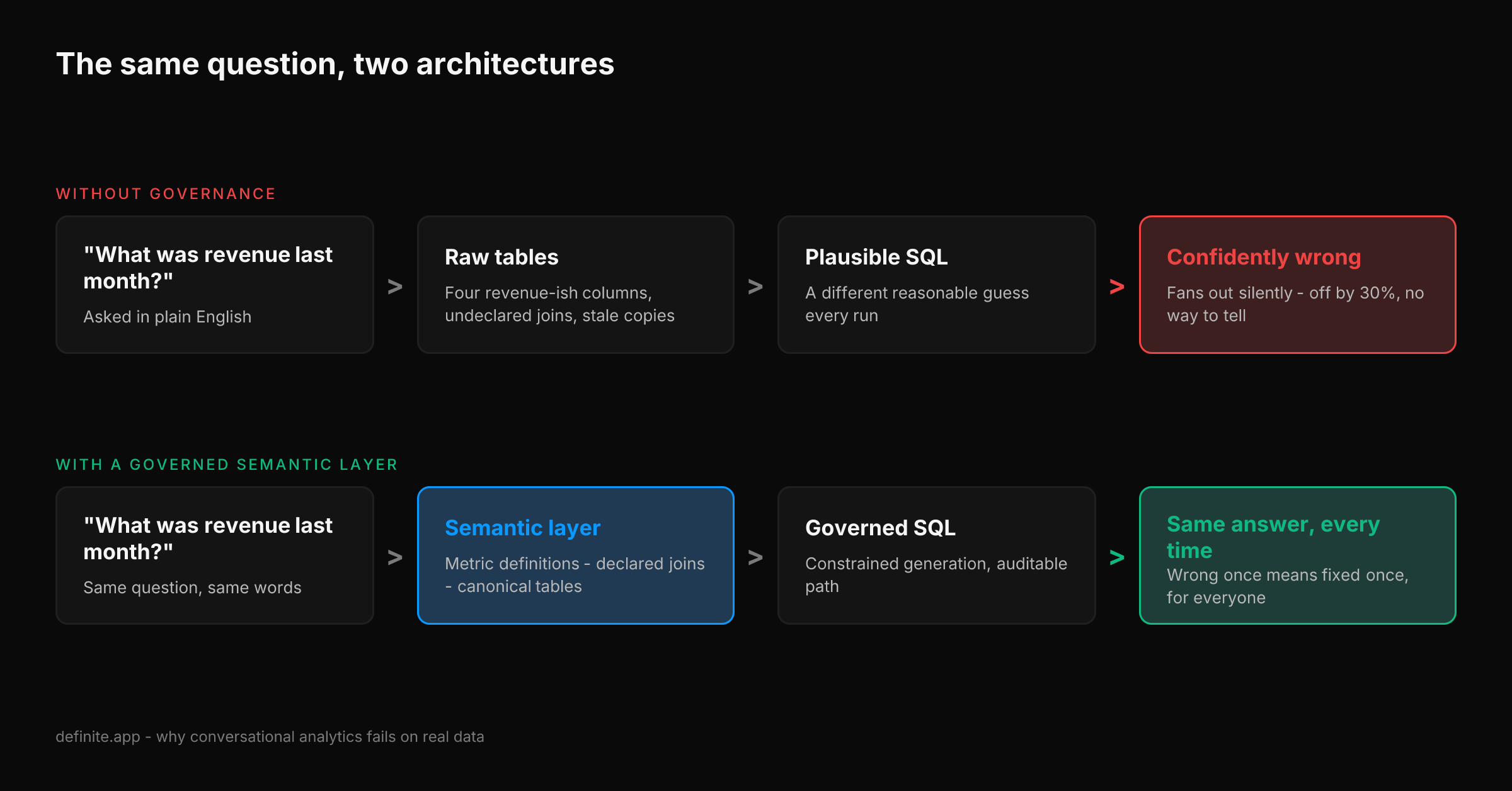
Strip the enterprise vocabulary away and a semantic layer, for this purpose, is the recorded version of the decisions your company already made:
- Metric definitions. Revenue means
SUM(orders.total_amount) - refunds, excluding test accounts. Written once, as code, not as tribal memory. - Declared join paths. Orders relate to refunds this way, not that way. The fan-out trap from earlier stops being guessable territory.
- Certified tables. Of the four revenue-ish columns, this is the canonical one; the 2023 analyst table is explicitly out.
- Descriptions and synonyms. "Churn," "logo churn," and "revenue churn" resolve to the right definitions even when the question is sloppy.
- Access rules. Who's allowed to ask about what — which matters the moment this stops being a demo.
What this buys the model is constraint. Text-to-SQL against raw tables is an open-ended generation problem: infinite plausible queries, one right answer, no way to tell them apart. The same question against governed definitions is a constrained problem: the metric is already defined, the joins are already declared, and the model's job shrinks to mapping language onto a vocabulary that's guaranteed to be correct.
And constraint isn't a cage. Not every question maps onto a predefined metric — exploratory questions, one-off investigations, and the long tail all require the agent to write free-form, expressive SQL. The layer earns its keep there too: certified tables, declared joins, and recorded definitions act as a map, so even when the agent ranges beyond the governed metrics, it starts from what's canonical instead of guessing among four revenue columns. Governed answers where definitions exist, grounded exploration where they don't — that's the difference between a foundation and a fence.
One honest caveat, because the vendor pages won't say it: a semantic layer can itself be wrong or stale. Anthropic measured exactly this — their analytics agent's accuracy drifted from ~95% to ~65% within a month as schemas and definitions moved underneath it, and stayed fixed only once definition maintenance became part of the same engineering workflow that changes the data. Governance doesn't make errors impossible — it makes them findable and fixable once. A wrong certified metric gets corrected in one place and every future answer inherits the fix. A wrong guess against raw tables gets re-guessed, differently, tomorrow.
The one-person version
Here's where the prescription usually loses the people who need it most. "Build a governed semantic layer" sounds like "hire a data team" — and if you're the solo data person, you are the data team, and you didn't sign up for a six-month modeling project.
So scope it honestly, in two cuts. First: you don't need to model 250 tables. You need governed definitions for the metrics leadership actually asks about — and at most companies that's a couple dozen, not hundreds. Revenue, MRR, churn, CAC, active customers, pipeline. The recurring 80% of questions route through that short list — instead of through your DMs. Each correction — "exclude refunds," "net, not gross" — becomes a definition refinement, so the layer compounds instead of decaying.
Worth being clear-eyed about what the Anthropic result took, though: a dedicated data science and data engineering team building data foundations, a semantic layer, skill files, and a validation harness — and maintaining all of it as an ongoing engineering practice. That's the right recipe, and it's unrealistic for one person to cook from scratch. The honest options for a solo data person are a platform where that stack comes assembled, or scoping the DIY version down hard.
Second: even those couple dozen definitions no longer have to be hand-written. Since 2025, the same class of AI agent that needs the semantic layer has gotten good enough to draft a credible first pass of it. An agent can read your schema and your query history, propose the metric definitions, declared joins, and canonical tables, and leave you the only part that was ever truly human work: ratifying the decisions. Which revenue is canonical is still your call — and yes, that still means the meeting with finance; no agent can attend it for you. But the work shrinks to a review pass measured in days, not a quarter of hand-writing definitions.
The remaining cost is real but smaller than the prescription used to imply: connected sources, a warehouse, and a review pass over agent-drafted definitions, before the chat box earns trust. (Conversation is the last layer of the chain, not the first: connected data, then modeled data, then talk.) This is the architecture bet we've made with Definite — connectors, warehouse, semantic layer, and an AI analyst (Fi) that both drafts the semantic layer and grounds every answer in it. Not because our AI is infallible — no one's is, and the BIRD gap above applies to everyone — but because the architecture closes the loop: the agent works the entire stack, not one surface of it. It configures the connectors, models the data, drafts the definitions, and then answers questions constrained by the same definitions it drafted — so the same governed question gets the same answer, and a wrong answer gets fixed once, for everyone. That's the part a chat box bolted onto a BI tool can't reach: it can only see the last layer, and the failures live in the layers below.
The solved version already exists
The Reddit thread's skepticism is correct about every interface-first deployment — and it's already out of date as a verdict on the category. Anthropic runs the solved version internally today — 95% of its analytics queries answered by the agent, at better than 95% measured accuracy. It wasn't solved by a model release, because the model was never the missing piece. It gets solved company by company, the moment the foundation exists — at which point the conversation layer becomes almost boring: one surface of a governed system that an agent works end to end, alongside others (agents that watch, investigate, and report are next, and they need the same foundation even more).
The tell is already on the leaderboard: the top Spider 2.0 entries are systems with names like "Sentinel" and "Prism Swarm" — agents wrapped around context infrastructure, not bigger bare models. We're obviously not neutral about that conclusion; we bet the product on it. But it's a checkable bet: the other vendors concede it in their docs, the benchmarks demonstrate it, and your own schema will confirm it the first afternoon you try.
So: is conversational analytics actually a solved problem? Yes — where the foundation exists and an agent works the whole stack, it's in production right now. It stays unsolved in exactly one place: at the interface, where most vendors keep trying to sell it. Govern the couple dozen metrics your leadership actually asks about, and it's solved on your data this quarter. Skip that step, and no model — this year's or next year's — will save the demo from your schema.
If you'd rather evaluate the assembled version than build it, Definite will run on your own schema: connect a source, let Fi draft the first definitions, and see whether the answers earn trust.
FAQ
Is conversational analytics actually a solved problem? Yes, conditionally — it's solved at the foundation, not the interface. Anthropic's data team automates 95% of internal analytics queries at over 95% accuracy, and every production vendor grounds their version in a governed semantic layer. Deployments that bolt a chat UI onto ungoverned data keep failing, and will keep failing regardless of model improvements — the missing piece is governed context for the AI, not a smarter model.
Why does text-to-SQL give wrong answers on real databases when it works in demos? Demo schemas are small, clean, and unambiguous — one revenue column, obvious joins. Real schemas have ambiguous metric candidates, undeclared join logic, and institutional definitions that don't live in the database at all. The model fails because the information it needs was never written down, not because it can't write SQL. Spider 2.0 measured this directly: GPT-4o went from 86.6% on tutorial-style schemas to 10.1% on real enterprise workflows.
Do I need a semantic layer for AI analytics — and what's the minimum for one person? For trustworthy answers, yes — every production vendor grounds their conversational analytics in one. The minimum viable version is far smaller than the enterprise literature implies: governed definitions for the couple dozen metrics leadership actually asks about, with declared joins and a canonical table list. Not 250 modeled tables. And AI agents can now draft those definitions from your schema and query history — the human work is reviewing and ratifying them, not writing them.
Is conversational analytics fundamentally limited by LLMs? Mostly no. The benchmark record shows accuracy moves with the quality of context and governance, not model size — agentic systems climbed Spider 2.0 by engineering context, not by swapping models. But a governed foundation fixes the largest class of failures, not all of them: humans still outscore the best systems on BIRD by about 11 points, so treat any "hallucination-free" claim as a red flag.
What's the difference between conversational analytics and conversational BI? Effectively the same thing: asking questions of business data in natural language. One disambiguation matters more — "conversational analytics" also names a contact-center technology that analyzes support calls and chats (what IBM and NiCE mostly mean by the term). This post is about the BI sense.