Comparing Iceberg Query Engines

Iceberg Query Engines
Many in the data space are now aware of Iceberg and its powerful features that bring database-like functionality to files stored in the likes of S3 or GCS. But Iceberg is just one piece of the puzzle when it comes to transforming files in a data lake into a Lakehouse capable of analytical and ML workloads. Along with Iceberg, which is primarily a table format, a query engine is also required to run queries against the tables and schemas managed by Iceberg. In this post we explore some of the query engines available to those looking to build a data stack around Iceberg: Snowflake, Spark, Trino, and DuckDB.
DuckDB spoiler: if you want to see a demo of DuckDB + Iceberg jump down to the DuckDB section. Or if you just want the code, go here.
Snowflake
Though best known for its turnkey data warehouse that combines compute and storage into one product, Snowflake started supporting Iceberg tables a few years ago. With a Snowflake + Iceberg set up, Snowflake’s compute engine can be used to query Iceberg tables external to Snowflake. By pairing Snowflake compute with Iceberg, users can harness Snowflake features such as auto-scaling resources and access control policies. Snowflake’s compute costs may be a limitation for some but its out-of-the box readiness may be worth it. Another factor to consider is Databricks’ acquisition of core Iceberg contributor, Tabular, which could influence the future development of Iceberg in directions less optimized for Snowflake. Nonetheless Snowflake may be a good choice for those who already use the platform or those looking for a fully managed query engine.
Spark
Spark is another commonly used query engine for Iceberg. Having been designed for big data workloads, Spark works well with the large amounts of data typically found in data lakes. Spark’s parallelization optimizations along with its horizontal scalability (scales by increasing number of nodes) allow it to efficiently execute complex queries against large data sets. Furthermore, Spark supports querying Iceberg with both SparkSQL and Spark dataframes allowing developers and analysts flexibility in choosing their preferred method of data manipulation. Spark is also used in machine learning pipelines so integrating a Spark query engine for Iceberg may streamline workflows needed for ML/AI tasks. Though Spark is great for many big data use cases, it can be resource intensive and requires a decent amount of expertise to configure and optimize Spark clusters. For teams with the dedicated resources to manage Spark, it can be an excellent choice for complex big data and machine learning use cases.
Trino
Trino is also a popular query engine for Iceberg. Similar to Spark, Trino is an open source distributed compute engine but with a focus on SQL execution. Whereas Spark has a broad range of use cases, Trino’s singular focus on query execution allow it be relatively more lightweight compared to Spark. As a result management of Trino clusters is less labor intensive than managing Spark clusters, though some set up and maintenance is still required. Trino is also highly optimized for speed thanks to in-memory processing of frequently accessed data and parallel execution of query stages. In benchmarks, Trino tends to outperform Spark when it comes to query speed. For teams with the necessary resources to maintain the clusters, Trino is a good choice for use cases where high performance, low latency SQL querying is the top priority.
DuckDB
We’ve covered DuckDB in a previous post (How We Migrated From Snowflake to Duckdb) but it’s also shaping up to be a potential query engine for Iceberg as both projects continue developing.
DuckDB is open source (unlike Snowflake) and lighter weight than Spark or Trino. Operations are done in memory and can be performed on a single machine. Installing DuckDB is as simple as pip install duckdb and is deployable without complex configurations. Despite its simplicity DuckDB is highly performant, consistently ranking near the top of benchmarks (see here and here). In a 3 way comparison of using DuckDB, Spark, and Trino for dbt transformations, DuckDB was the fastest in most scenarios. However, depending on the memory constraints of the machine DuckDB is running on, it may not be a good choice for very large (multi-terabyte range) data sets. With that said given it’s strong performance on most medium to large data workloads and its easy setup, you may find that DuckDB strikes the right balance between performance and maintenance overhead.
DuckDB + Iceberg Example
We will be loading 12 months of NYC yellow cab trip data (April 2023 - April 2024) into Iceberg tables and demonstrating how DuckDB can query these tables.
We first read the trips and zones (pickup/drop off locations) data from the NYC taxi site.
import duckdb
import pyarrow as pa
# get data from April 2023 to April 2024
trips_ls = []
months = [
'2023-04',
'2023-05',
'2023-06',
'2023-07',
'2023-08',
'2023-09',
'2023-10',
'2023-11',
'2023-12',
'2024-01',
'2024-02',
'2024-03',
'2024-04'
]
for month in months:
table_path = f'https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_{month}.parquet'
# NOTE: this initial data read doesn't require Duckdb, something like pandas works as well
table = duckdb.sql(f"SELECT * FROM '{table_path}'").arrow()
trips_ls.append(table)
# concatenate all monthly trips data into one pyarrow table
trips = pa.concat_tables(trips_ls)
# get location zone mapping
zones = duckdb.sql("SELECT * FROM 'https://d37ci6vzurychx.cloudfront.net/misc/taxi_zone_lookup.csv'").arrow()
Here is the schema for trips (41,994,806 rows):
VendorID: int32
tpep_pickup_datetime: timestamp[us]
tpep_dropoff_datetime: timestamp[us]
passenger_count: int64
trip_distance: double
RatecodeID: int64
store_and_fwd_flag: string
PULocationID: int32
DOLocationID: int32
payment_type: int64
fare_amount: double
extra: double
mta_tax: double
tip_amount: double
tolls_amount: double
improvement_surcharge: double
total_amount: double
congestion_surcharge: double
Airport_fee: double
and here is the schema for zones (265 rows):
LocationID: int64
Borough: string
Zone: string
service_zone: string
Now that we have our data let’s setup Iceberg. To do this we use PyIceberg, a Python library for interacting with Iceberg tables. The first step is to create an Iceberg catalog. The catalog is essentially comprised of pointers that direct the query engine on how to read the data such as where to find the data, what the schema is, how it is partitioned, and if any manipulations have been applied to it. In our demo we will use sqlite for the catalog:
from pyiceberg.catalog.sql import SqlCatalog
# create iceberg catalog using sqlite
warehouse_path = "SET_YOUR_PATH"
name_space = "demo_db"
catalog = SqlCatalog(
name_space,
**{
"uri": f"sqlite:///{warehouse_path}/pyiceberg_catalog.db",
"warehouse": f"file://{warehouse_path}",
},
)
# create a namespace for Iceberg
catalog.create_namespace(name_space)
Notice in the last line above we created a name space, demo_db, which will be where the actual data gets loaded into.
We also add two helper functions needed to ensure that every table’s catalog and metadata are properly synced. This is to address the Github issue mentioned here:
import sqlite3
def get_iceberg_tables(database_path, table_namespace=None, table_name=None):
"""
Connect to the SQLite database and retrieve the list of Iceberg tables.
Optionally filter by namespace and table name.
Parameters:
database_path (str): The path to the SQLite database file.
table_namespace (str, optional): The namespace of the table to search for.
table_name (str, optional): The name of the table to search for.
Returns:
list: A list of dictionaries, each representing an Iceberg table.
Raises:
ValueError: If only one of table_namespace or table_name is provided.
"""
# Check if both namespace and table name are provided together
if (table_namespace and not table_name) or (table_name and not table_namespace):
raise ValueError("Both table_namespace and table_name must be provided together.")
# Connect to the SQLite database
con_meta = sqlite3.connect(database_path)
con_meta.row_factory = sqlite3.Row
# Create a cursor object to execute SQL queries
cursor = con_meta.cursor()
# Base query to list tables in the database
query = 'SELECT * FROM "iceberg_tables" WHERE 1=1'
params = []
# Add conditions to the query based on provided namespace and table name
if table_namespace and table_name:
query += ' AND "table_namespace" = ? AND "table_name" = ?'
params.append(table_namespace)
params.append(table_name)
# Execute the query with parameters
cursor.execute(query, params)
# Fetch all results
results = cursor.fetchall()
# Convert results to list of dictionaries
table_list = []
for row in results:
row_dict = {key: row[key] for key in row.keys()}
table_list.append(row_dict)
# Close the connection
con_meta.close()
return table_list
def create_metadata_for_tables(tables):
"""
Iterate through all tables and create metadata files.
Parameters:
tables (list): A list of dictionaries, each representing an Iceberg table with a 'metadata_location'.
"""
for table in tables:
metadata_location = table['metadata_location'].replace('file://', '')
metadata_dir = os.path.dirname(metadata_location)
new_metadata_file = os.path.join(metadata_dir, 'v1.metadata.json')
version_hint_file = os.path.join(metadata_dir, 'version-hint.text')
# Ensure the metadata directory exists
os.makedirs(metadata_dir, exist_ok=True)
# Copy the metadata file to v1.metadata.json
shutil.copy(metadata_location, new_metadata_file)
print(f"Copied metadata file to {new_metadata_file}")
# Create the version-hint.text file with content "1"
with open(version_hint_file, 'w') as f:
f.write('1')
print(f"Created {version_hint_file} with content '1'")
Next we register the PyArrow tables into the catalog and load the data into Iceberg tables in the demo_db namespace:
# add tables to iceberg
for table, table_name in [
(trips, "trips"),
(zones, "zones"),
]:
# create the iceberg table
iceberg_table = catalog.create_table(
f"{name_space}.{table_name}",
schema=table.schema,
)
# add data to iceberg table
iceberg_table.append(table)
# copy catalog metadata to iceberg table
catalog_records = get_iceberg_tables(f"{warehouse_path}/pyiceberg_catalog.db", name_space, table_name)
create_metadata_for_tables(catalog_records)
print(f"Created {table_name}, {table.num_rows} rows")
Before hooking up DuckDB to query the data let’s take a look at what we just created. You should see a file called pyiceberg_catalog.db. This is a sqlite database with pointers to data and metadata of our Iceberg instance.
You should also see a directory called demo_db.db , which is where the metadata and data is actually stored. Expanding the full demo_db.db directory should look like this:
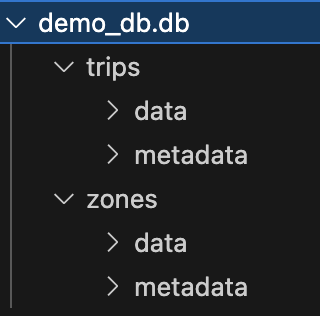 Each subdirectory represents an Iceberg table (eg
Each subdirectory represents an Iceberg table (eg trips and zones). The data folder is where the actual data is saved in parquet format. The metadata folder contains information used by the query engine such as which parquet file is the latest, how to partition the data, how to manipulate parquet files, etc.
Now we connect DuckDB to Iceberg. First we initiate a DuckDB connection, install the DuckDB Iceberg extension, create a schema called taxi, and create views of the trips and zones Iceberg tables:
# initiate a duckdb connection which we will use to be the query engine for iceberg
con = duckdb.connect(database=':memory:', read_only=False)
setup_sql = '''
INSTALL iceberg;
LOAD iceberg;
'''
res = con.execute(setup_sql)
# create the schema and views of iceberg tables in duckdb
database_path = f'{warehouse_path}/demo_db.db'
create_view_sql = f'''
CREATE SCHEMA IF NOT EXISTS taxi;
CREATE VIEW taxi.trips AS
SELECT * FROM iceberg_scan('{database_path}/trips', allow_moved_paths = true);
CREATE VIEW taxi.zones AS
SELECT * FROM iceberg_scan('{database_path}/zones', allow_moved_paths = true);
'''
con.execute(create_view_sql)
Querying Iceberg With Duckdb
Let’s run some queries and time it. For reference my local machine is a mid-2021 Macbook with the M1 chip and 32gb of RAM.
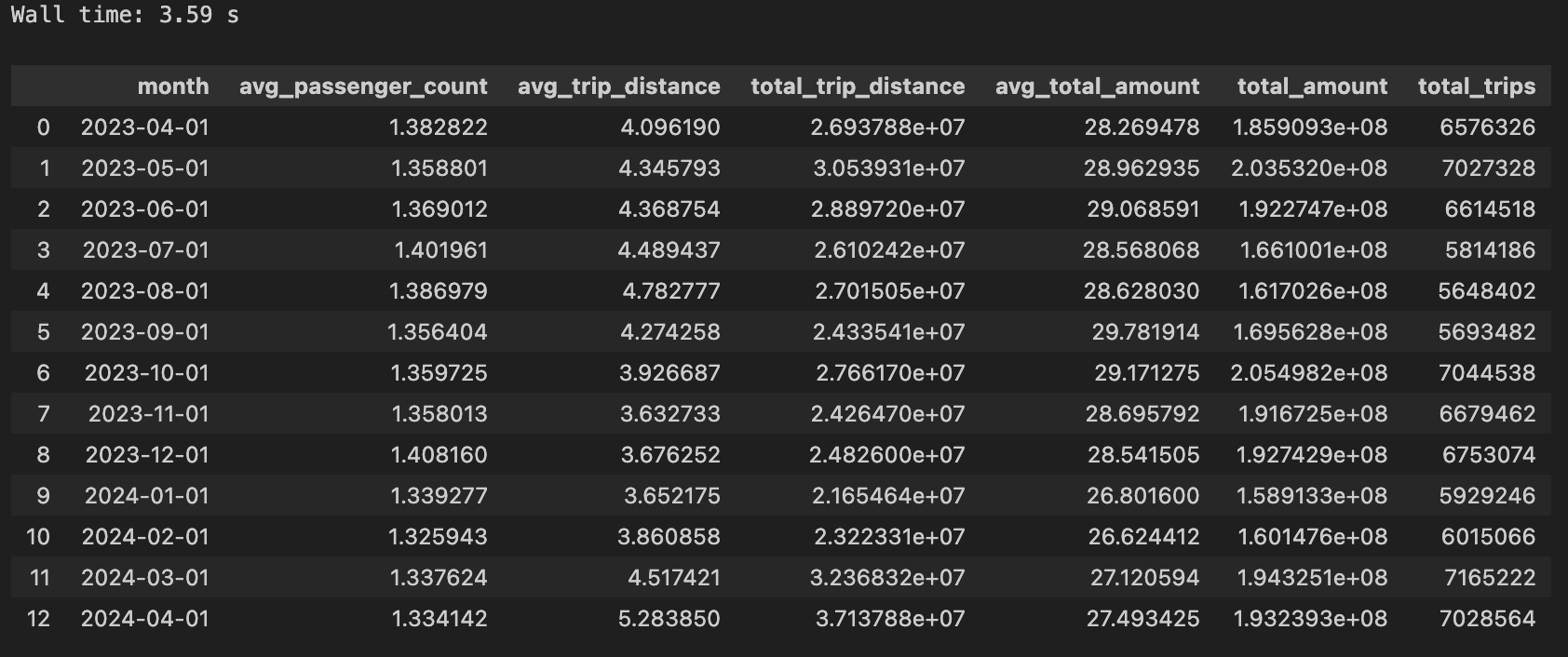
Monthly Aggregated Trip Statistics
sql = f'''
select
date_trunc('month', tpep_pickup_datetime) as month,
avg(passenger_count) as avg_passenger_count,
avg(trip_distance) as avg_trip_distance,
sum(trip_distance) as total_trip_distance,
avg(total_amount) as avg_total_amount,
sum(total_amount) as total_amount,
count(*) as total_trips
from taxi.trips
-- some data present is pre and post our target date range, so we filter it out
where tpep_pickup_datetime between '2023-04-01' and '2024-05-01'
group by 1
order by 1
'''
%time res = con.execute(sql)
res.fetchdf()
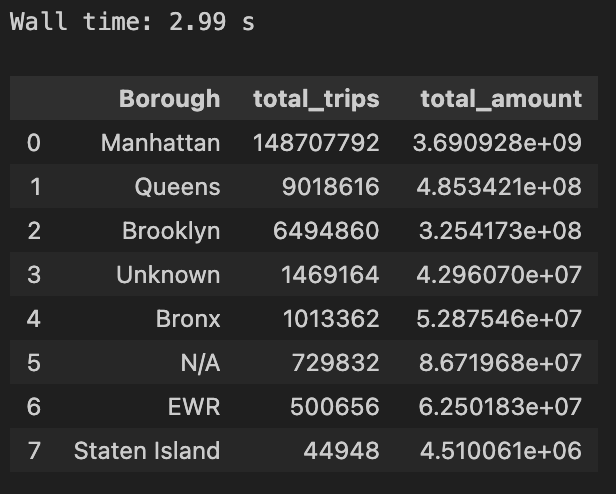
Total Trips and Total Fare Amount By Borough (1 join, sorted):
sql = f'''
select
zones.Borough,
count(*) as total_trips,
sum(total_amount) as total_amount
from taxi.zones as zones
left join taxi.trips as trips
on zones.LocationID = trips.DOLocationID
group by 1
order by 2 desc
'''
%time res = con.execute(sql)
res.fetchdf()
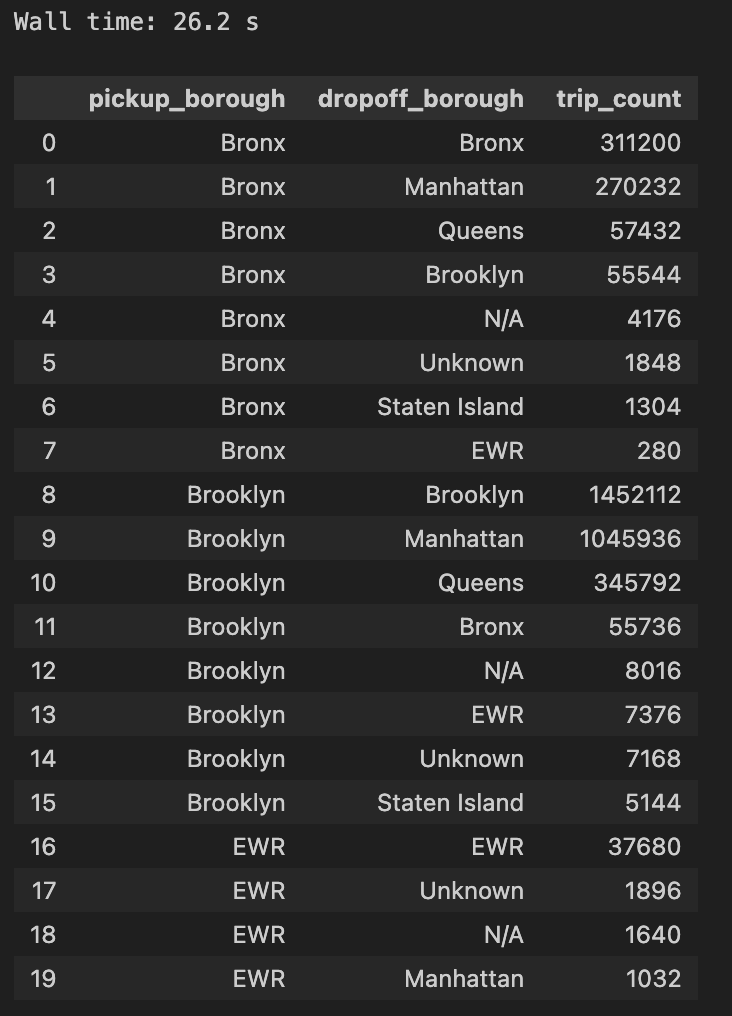
 Total Trips By Pickup and Drop-off Borough (2 joins, sorted):
Total Trips By Pickup and Drop-off Borough (2 joins, sorted):
sql = f'''
select
starting_zone.Borough as pickup_borough,
ending_zone.Borough as dropoff_borough,
count(*) as trip_count
from
taxi.trips as trips
left join taxi.zones as starting_zone
on trips.PULocationID = starting_zone.LocationID
left join taxi.zones as ending_zone
on trips.DOLocationID = ending_zone.LocationID
group by 1, 2
order by 1 asc, 3 desc
'''
%time res = con.execute(sql)
res.fetchdf().head(20)
 Even on a relatively large data set (42 million rows), DuckDB and Iceberg are able to run queries in a reasonable amount of time on just a laptop. The added benefit of implementing Iceberg instead of using DuckDB alone is that we can apply CRUD operations on an otherwise static set of parquet files. Imagine we wanted to update the schema of the taxi data, update records, or append new data, Iceberg allows us to perform these actions in a more database-like fashion. Furthermore with DuckDB we can create views to define transformation logic on top of Iceberg tables. Since this post was published the two projects have matured considerably — predicate pushdown landed and DuckDB added Iceberg write support (INSERT/UPDATE/DELETE) in v1.4 — and Duck + Iceberg has become an increasingly attractive option for building and querying a Lakehouse.
Even on a relatively large data set (42 million rows), DuckDB and Iceberg are able to run queries in a reasonable amount of time on just a laptop. The added benefit of implementing Iceberg instead of using DuckDB alone is that we can apply CRUD operations on an otherwise static set of parquet files. Imagine we wanted to update the schema of the taxi data, update records, or append new data, Iceberg allows us to perform these actions in a more database-like fashion. Furthermore with DuckDB we can create views to define transformation logic on top of Iceberg tables. Since this post was published the two projects have matured considerably — predicate pushdown landed and DuckDB added Iceberg write support (INSERT/UPDATE/DELETE) in v1.4 — and Duck + Iceberg has become an increasingly attractive option for building and querying a Lakehouse.
All the code in the demo can be found here.