Databricks Alternatives: Most Companies Are Searching for the Wrong Thing

Every "Databricks alternatives" article you'll find lists the same eight to ten platforms. Snowflake, BigQuery, Redshift, Microsoft Fabric, Apache Spark. Sometimes Starburst. Sometimes Dremio.
What almost none of them tell you: most of those platforms don't solve the problem that made you search for a Databricks alternative. They're just a different infrastructure layer to build on top of.
If you're in the middle of a data stack evaluation that's starting to feel like a trap — six months of implementation, five vendor contracts, and a data engineer hire you weren't planning on — this guide is structured differently. It starts with who you actually are. And for many teams searching this query, the right answer isn't a different platform to build on. It's something that makes building unnecessary.
Who this guide is for: Growth-stage companies (roughly Series A through C) and small data teams whose workloads don't require what Databricks actually does. If you're an enterprise data engineering team evaluating Spark-at-scale, Unity Catalog, or Delta Lake compatibility, this post isn't pitched at the right level.
What Databricks Actually Does (And Who It's For)
Databricks is a data platform built for data engineering and machine learning teams with large-scale workloads. Core capabilities: data transformation at scale using Apache Spark, ML model training and feature engineering, Delta Lake / Iceberg storage, Unity Catalog governance, and Databricks SQL for analytical queries.
What Databricks doesn't ship with: SaaS data connectors — you'll need Fivetran or Airbyte to ingest from Salesforce, HubSpot, Stripe, and similar tools. A business intelligence layer (AI/BI Genie, launched in 2024, helps at the margins, but most Databricks teams still run a separate BI tool). A semantic layer for defining consistent business metrics across your team. These are documented partner integrations — expected parts of a Databricks stack, not optional extras.
The result: a working Databricks analytics setup typically means five tools and five contracts. Databricks plus Fivetran or Airbyte, plus dbt, plus a BI tool, plus an orchestration layer. Significant setup and ongoing engineering time before you see a single dashboard.
The Alternatives at a Glance
Most listed alternatives are also infrastructure platforms — choosing them is still a decision to assemble and operate a stack.
| Alternative | What it solves | What you still build separately |
|---|---|---|
| Snowflake | Storage + SQL compute | ETL, BI layer, semantic layer |
| BigQuery | Serverless SQL + storage | ETL, BI layer, semantic layer |
| Microsoft Fabric | Unified data + Power BI | ETL setup, data engineering config |
| Amazon Redshift | SQL warehouse | ETL, BI layer, semantic layer |
| Apache Spark (self-managed) | Compute flexibility | Everything else |
| Trino / Starburst | SQL on open storage | Storage setup, ETL, BI |
Definite isn't in this table because it's a different answer to a different question: every platform above is infrastructure you build on top of. Definite replaces the need to build. Jump to the Definite section →
Three Types of Teams Searching for Databricks Alternatives
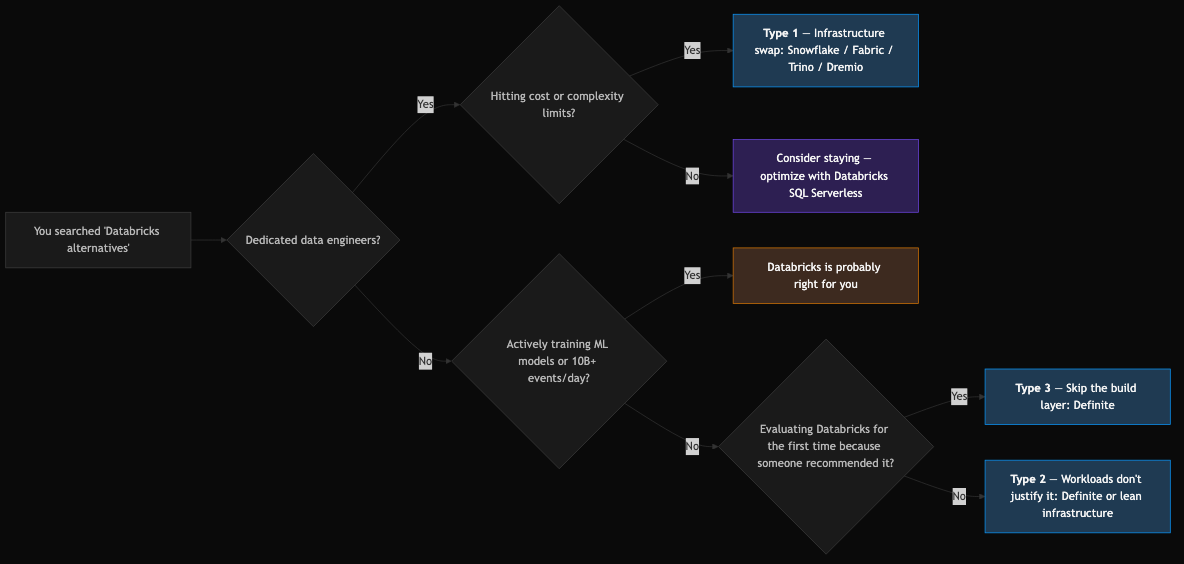
Getting to the right recommendation requires being honest about which situation you're in.
Type 1: You Have a Data Team and Want Better Infrastructure
If you have dedicated data engineers, real pipeline workloads, and you've hit cost or complexity limits on Databricks, you're in the market for a genuine infrastructure swap.
Microsoft Fabric — Microsoft's unified analytics platform combining Power BI, Synapse Analytics, and Azure Data Factory under a single capacity-based license. Reached GA in November 2023. For teams deep in the Microsoft ecosystem, Fabric consolidates multiple tooling layers into one contract and one governance model. Tradeoff: Azure-only, and capacity pricing scales quickly (meaningful workloads typically require F64 at ~$6,291/month or higher).
Snowflake — The most common Databricks competitor for SQL-heavy analytics. The products have converged significantly since 2022 — Snowflake added Iceberg table support (GA'd 2024), Notebooks, and Snowpark ML; Databricks added SQL analytics and AI/BI Genie. For teams that don't rely on Spark-based ML pipelines, Snowflake is a clean alternative. Still requires ETL and BI layers separately. (See Databricks vs Snowflake 2026 for a full head-to-head.)
Trino / Starburst — Open-source distributed SQL query engine for teams that want to query data in place (on S3, GCS, ADLS) without proprietary storage lock-in. Starburst is the managed commercial version. Strong choice if your team wants open-source control over the lakehouse query layer. Not lower-complexity than Databricks — differently complex. Requires technical expertise to operate.
Dremio — Positioned explicitly as an open lakehouse alternative to Databricks. Dremio Cloud (fully managed) has lowered the operational barrier significantly vs. self-managed Trino. Good option for teams that want lakehouse query capabilities on Iceberg or Delta Lake without Databricks platform lock-in.
Google BigQuery / Amazon Redshift — Warehouse-first architectures that handle most SQL analytics workloads without cluster management. Google has extended BigQuery toward lakehouse territory with BigLake; AWS launched S3 Tables (Iceberg-native) at re:Invent 2024. Strong picks for cloud-native analytics teams already committed to Google Cloud or AWS respectively.
Type 2: Your Workloads Don't Justify What Databricks Does
This is actually the bigger group.
The Databricks use case — Spark-based large-scale data transformation, ML model training, petabyte data volumes — is genuinely the right tool for teams doing those things. But many companies evaluating Databricks are running SQL analytics on SaaS data: CRM, payments, product events. One to three data engineers writing SQL and Python, not Spark jobs. Dashboards and governed metrics, not feature stores.
For these teams — small data engineering teams with SQL-first workloads, startups without dedicated data engineers — Databricks is overhead, not capability. The cluster management, DBU billing complexity, and the five-tool stack around it are solving problems you don't have.
Databricks SQL Serverless has narrowed this gap — it eliminates cluster management for SQL-only workloads and can be cost-effective at low query volumes. But the surrounding stack (ETL, modeling, BI) remains your problem to assemble.
The cost reality: for a 75-person B2B SaaS company, a typical Fivetran + Snowflake + Tableau stack runs around $2,800/month in tooling alone. Add a 0.5 FTE data engineer (at ~$180K loaded) and you're approaching $24,000/month in fully loaded data costs — for a stack that's still assembling itself.
Type 3: You're Evaluating Databricks for the First Time
You were told Databricks is the right answer. Now you're doing due diligence and wondering if it actually fits a company your size.
Your head of data engineering wants Databricks because it's credible. Your board wants "a data strategy." You want to know why it's going to take six months and multiple vendor contracts before your CFO can see a single dashboard. The honest answer: for most Series A and B companies, Databricks is solving problems that haven't arrived yet.
A useful test: does your analytics work mostly come down to answering business questions from your SaaS tools — things like MRR by segment, campaign attribution, churn cohorts? That's not a Spark problem. Databricks is a very expensive way to answer those questions.
The indicator that Databricks is the right call: you're training ML models at scale, processing tens of billions of events per day, or you have a data engineering team that's already outgrowing simpler infrastructure. For most Series A and B companies, those problems arrive later if at all.
Type 3 evaluators aren't choosing between infrastructure options. They're choosing whether to build infrastructure at all — or skip to answers.
Definite: The All-In-One Alternative
The right alternative to Databricks for most growth-stage teams isn't a different platform to build on top of — it's a platform that makes building unnecessary.
Definite connects your data sources, shapes that data into governed metrics, and delivers answers through dashboards, scheduled reports, and AI — all in one system, with no infrastructure to assemble. For a team that needs analytics running within days rather than months, this is what "done" looks like.
Where Definite Fits Better Than Databricks
For the situations where Databricks is commonly evaluated at growth-stage companies, Definite is more capable in the ways that matter:
- Time to first dashboard: Hours to days, not months. Connect a data source, define a metric, build a dashboard — no infrastructure setup, no cluster configuration, no waiting for a data engineer to finish the pipeline.
- No assembly required: ETL, warehouse, semantic layer, dashboards, and AI all work together out of the box. There's no Fivetran contract to negotiate, no dbt project to maintain, no BI tool to license separately.
- Non-technical self-serve: Your CFO, head of marketing, or VP of Sales can answer their own data questions without waiting for an analyst. Most infrastructure alternatives require SQL knowledge to get value from the platform.
- AI that acts, not just answers: Because Definite owns the full stack — ingestion through semantic layer through presentation — the AI has context to build, modify, and act on your data. AI analytics tools that run on top of a fragmented stack inherit all of its problems: inconsistent metrics, fragmented governance, no ability to act. Definite's AI is built into the data model.
- Open standards, no lock-in: Iceberg tables, Cube.js models, DuckDB SQL, Python SDK. Your data is in open formats. When your workloads eventually outgrow Definite, migration is moving files — not rebuilding from scratch.
What's Included
Ingestion, storage, and SQL access — 500+ managed connectors for Salesforce, HubSpot, Stripe, Shopify, Postgres, BigQuery, Google Analytics, and many more. No Fivetran contract, no Airbyte self-hosting. The built-in warehouse (DuckLake) stores data in Apache Iceberg tables on Google Cloud Storage — the same open format Databricks reportedly paid over $1 billion to acquire control of in June 2024. Full DuckDB SQL access lets analysts write arbitrary queries when needed; non-technical users get governed dashboards without touching SQL. Your data isn't locked in — if you ever leave, it leaves with you.
Metrics, AI, and automation — Built on Cube.js (open-source), Definite's semantic layer lets you define key metrics once — MRR, LTV, win rate — and those definitions stay consistent everywhere: dashboards, AI queries, exports. No metric drift. No "whose number is right?" conversations. Fi, the AI assistant, answers plain-English questions backed by those governed metrics, builds and modifies dashboards on demand, and sends scheduled reports to Slack or email. Python pipelines handle multi-step workflows, DAG-based scheduling, and reverse ETL back to your CRM. An MCP server lets external AI agents (Claude, Cursor, and others) query your data and manage integrations programmatically.
Honest tradeoff: DuckDB runs on a single machine, not a distributed cluster like Spark. For the SQL analytics workloads most growth-stage companies actually run — typically under 100GB in active query sets — it handles queries quickly and at far lower operational overhead than distributed infrastructure. If you're processing billions of events per day or training large ML models, Definite isn't the answer. But for the companies reading this guide, that constraint is rarely the relevant one.
How to Decide
| Your situation | Recommended path |
|---|---|
| Large data team, ML/AI at scale, petabyte data | Databricks is the right tool |
| Deep Azure commitment, enterprise BI | Microsoft Fabric |
| SQL-first, existing dbt setup, enterprise scale | Snowflake |
| Open-source control, lakehouse without format lock-in | Trino/Starburst or Dremio |
| Google Cloud-first | BigQuery |
| AWS-first | Redshift Serverless |
| Growth-stage, no dedicated data team, need analytics fast | Definite |
| Small data team, SQL-first, no ML/Spark workloads | Definite (or Snowflake if you're willing to assemble ETL and BI separately) |
| Already on Databricks, want to reduce stack maintenance | Evaluate Definite for consolidation |
| On-premise data residency requirements | Self-managed Spark, IOMETE, or a self-hostable full stack |
Frequently Asked Questions
Is Databricks worth it for a startup?
For most startups: not yet. The real question is whether your analytics needs are SQL-on-SaaS-data problems (they usually are at early stage) or Spark-and-ML problems (they rarely are before Series C). If it's the former, Databricks is a very expensive way to answer questions that a purpose-built analytics platform answers faster, with less overhead, and without a six-month implementation.
What does Databricks not include?
ETL connectors for SaaS tools, a semantic layer for defining metrics, and a full business intelligence layer. You'll need Fivetran or Airbyte for data ingestion, dbt for data modeling, and a BI tool for dashboards — all separate contracts and separate engineering overhead. Databricks SQL and AI/BI Genie have improved, but most Databricks teams still run a separate BI tool.
Is Snowflake a Databricks alternative?
For SQL-heavy analytics: yes. For ML model training and large-scale Spark-based transformation: it's not a direct substitute. For the typical startup evaluating both, the distinction rarely matters — workloads at that stage are SQL analytics, not ML pipelines. Snowflake still requires ETL and BI tools separately.
What is Microsoft Fabric?
Microsoft's unified analytics platform: Power BI, Synapse Analytics, and Azure Data Factory under a single capacity-based license. GA'd November 2023. Strong alternative for Azure-native enterprises already running Power BI. Less practical for startups or cloud-agnostic teams.
What's the deal with Apache Iceberg vs. Delta Lake?
Delta Lake was Databricks' proprietary storage format. Iceberg is the open standard backed by Netflix, Apple, AWS, Google, and Snowflake. By 2024–2025, Iceberg had become the default for new lakehouse deployments outside Databricks. Databricks' acquisition of Tabular — the company founded by Iceberg's creators — was a recognition that Iceberg was already winning outside their ecosystem. Today both formats have converged significantly; Delta Lake has added Iceberg compatibility.
Can Databricks run on-premise?
Not fully. The classic compute plane and your tables live in your own cloud account, but the control plane (UI, scheduler, Unity Catalog, model serving) always runs in Databricks SaaS and requires a live connection. If the requirement is that nothing leaves your environment, including the AI layer, what you actually need is a self-hostable data stack with a private AI data analyst.
Do I need a data engineer to run most Databricks alternatives?
For infrastructure platforms (Snowflake, BigQuery, Fabric, Trino): yes, for setup and ongoing maintenance. Databricks SQL Serverless lowered the operational floor for SQL-only workloads. Definite is designed so that an analyst, ops lead, or non-technical exec can run it without a data engineering hire.
The Right Question
The "Databricks alternatives" search usually starts with a platform name and ends with a list of other platform names. It rarely asks whether the framing was right in the first place.
The right question isn't which platform to build on. It's whether you need to build at all.
For teams that genuinely need what Databricks does — Spark-scale ML, complex pipelines, enterprise governance — the infrastructure alternatives above are the honest options.
For teams that don't, the answer is a platform that replaces the need to assemble a stack entirely: data flowing in, governed metrics you can trust, and answers available to everyone in your company — without a six-month implementation or a data engineer on retainer to keep it running.
If you're not sure where you land, the cost calculator is the fastest way to see what your current path actually costs — or see how Definite compares to Databricks directly.
What could your data tell you?
Enter your domain and we’ll show you the business questions your tools can already answer — you just can’t ask them yet.
Try it with any company domain — no signup required.