Introducing Python support in Definite

We're on a mission to make Definite the world's best and most complete data platform. Of course, we already provide an AI analyst plugged into all your business data, vast visualization capabilities, connections to over 500 data sources, and a blazing-fast data warehouse. But despite all that, some of the sharpest 100x analysts we know keep asking for one thing: Python support.
Today, we’re proud to announce: Definite now supports Python! 🐍
The feature we playfully refer to as, Guido opens up a whole new world of possibilities. Whether you're scoring leads with machine learning, enriching data from external APIs, or running natural language processing on your textual data — you can now do it all directly inside Definite using Python.
We could just talk about the cool things you can do with Python, but we know what the people want: a practical tutorial with a real-world example. So let’s move on from the marketing and get into the code!
Python in action
To set the stage for our tutorial, imagine our sales team wants to identify companies in our CRM that match a specific profile — in this case, "creative agencies that do branding."
We’ll walk through the full workflow in three steps:
- Run a simple Python script in Definite
- Score each company based on its similarity to our target criteria
- Send those scores back to the CRM so the sales team can take action
Along the way, you’ll learn how to:
- Query your data using Python in Definite
- Visualize the output
- Run lightweight machine learning with scikit-learn
- Write results to your Definite data lake
- Push data back to external systems like your CRM
Let’s get started.
1. Get up and running 🐍
Let’s start simple. Here’s a lightweight Definite script that pulls company names and descriptions from Attio and returns them as a result. If you've never written a script in Definite before, note the use of the set_result() function at the end — that’s what displays the output back in the UI.
from definite_sdk.client import DefiniteClient
import requests
import pandas as pd
client = DefiniteClient(api_key=DEFINITE_API_KEY, api_url="https://api.definite.app")
query = """
SELECT
c.record_id,
c.name,
c.description
FROM "ATTIO"."companies" AS c
WHERE c.description IS NOT NULL
LIMIT 100
"""
res = requests.post(
url="https://api.definite.app/v1/query",
json={'sql': query},
headers={"Authorization": f"Bearer {DEFINITE_API_KEY}"},
)
df = pd.DataFrame(res.json().get("data", []))
set_result({'data': df.to_dict(orient='records')})
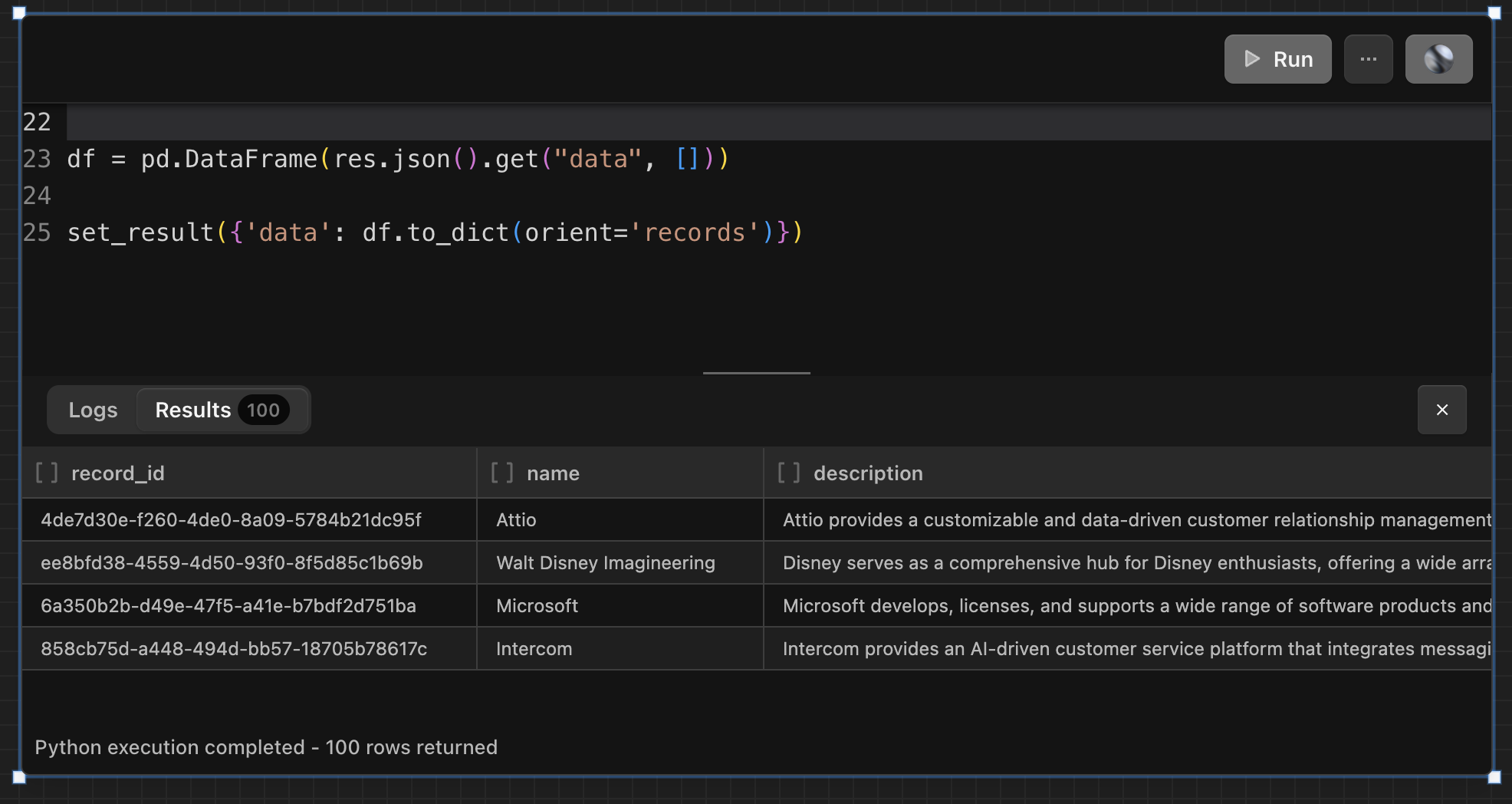
This looks exactly like what we expect it to. But we could have done this with plain SQL so let’s do something a little more interesting. Let’s get to the actual use case…
2. Score each account with TF-IDF and cosine similarity then store the results
The objective of this exercise was to find accounts in our CRM that resemble the criteria “"creative agencies that do branding.” Of course we could write clever a clever WHERE to filter the accounts with rules we make up. Or we could vibe code a script that uses a classic NLP technique to for some clever filtering. The path forward is obvious.
Next, we’ll do two things:
- Score each company by how well their description matches target text criteria with a classic NLP technique: TF-IDF vectorization combined with cosine similarity.
- Save those scores to a (DuckLake) table in Definite for future analytics and activation.
Note: This is one example of the numerous ways you could use Python to transform or enrich your data. Here are a few others:
- Machine learning with scikit-learn
- Data enrichment from providers like Clearbit or Apollo
- Text generation and classification from LLM services like GPT
If you’re unfamiliar with TF-IDF, it is fast, transparent, and runs entirely inside Python. As you can see below, the script query CRM data and grab the company descriptions and transform them into vectors so we can score the companies by their similarity to the target criteria.
Finally, the script uses Definite’s DuckLake integration to save the scores for later use.
import os
import pandas as pd
import requests
import duckdb
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
from definite_sdk.client import DefiniteClient
# 🔐 Initialize Definite client and Duck Lake connection
client = DefiniteClient(api_key=os.environ["DEFINITE_API_KEY"], api_url="https://api.definite.app")
conn = duckdb.connect()
conn.execute(client.attach_ducklake())
# 🎯 Define the query string to compare descriptions against
query_string = "Creative agency offering branding."
# 📥 SQL query to fetch company records with descriptions from Attio
query = """
SELECT DISTINCT
c.record_id,
c.name,
c.description
FROM "ATTIO"."companies" AS c
WHERE c.description IS NOT NULL
"""
# 🔗 Send SQL query to Definite API
res = requests.post(
url="https://api.definite.app/v1/query",
json={'sql': query},
headers={"Authorization": f"Bearer " + os.environ["DEFINITE_API_KEY"]},
)
# 📄 Extract result data
data = res.json().get("data", [])
# 🧱 Create a DataFrame from the query results
df = pd.DataFrame(data)
# 🧠 Compute TF-IDF vectors for all descriptions plus the query string
corpus = df['description'].tolist() + [query_string]
vectorizer = TfidfVectorizer(stop_words='english')
tfidf_matrix = vectorizer.fit_transform(corpus)
# 📏 Calculate cosine similarity between each description and the query string
tf_idf_similarities = cosine_similarity(tfidf_matrix[-1], tfidf_matrix[:-1]).flatten()
df['tf_idf_similarity'] = tf_idf_similarities
# 🔢 Convert similarity score to 0–100 scale (rounded)
df['similarity_score'] = (df['tf_idf_similarity'] * 100).round().astype(int)
# 📊 Select top 100 and keep only ID and score
df_output = df[['record_id', 'similarity_score']].sort_values('similarity_score', ascending=False).head(100)
# 🪵 Write results to Duck Lake table ATTIO.companies_scores
conn.execute("CREATE SCHEMA IF NOT EXISTS lake.attio;")
conn.register("df_output", df_output)
conn.execute("""
CREATE OR REPLACE TABLE lake.attio.companies_scores AS
SELECT * FROM df_output
""")
After scoring those stores in the data lake, I can query the table I created to check to see if they exist. The DuckLake integration provides a lake schema to write data too and that’s exactly where I put the new table. Here’s what the stored data looks like.
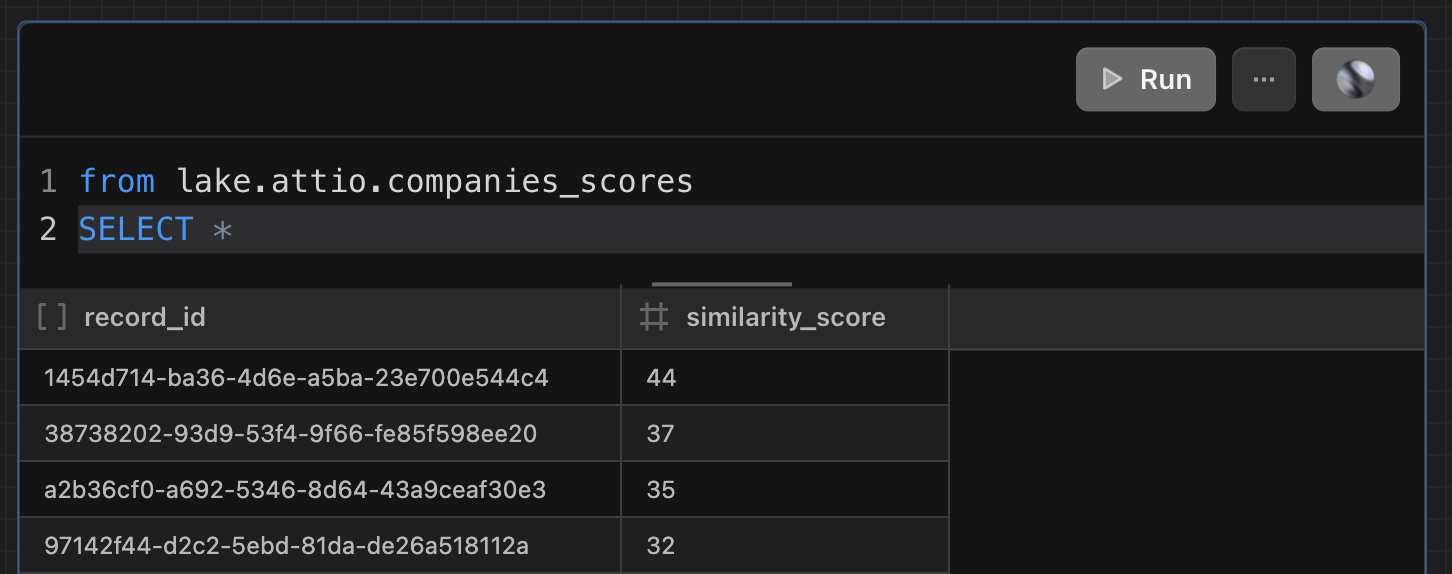
3. Sync the score back to our CRM
Now let’s close the loop. We’ve scored our companies and we've stored them in Definite. Now we want to send those scores back to Attio so our sales team can use them in views, filters, and workflows.
To do that:
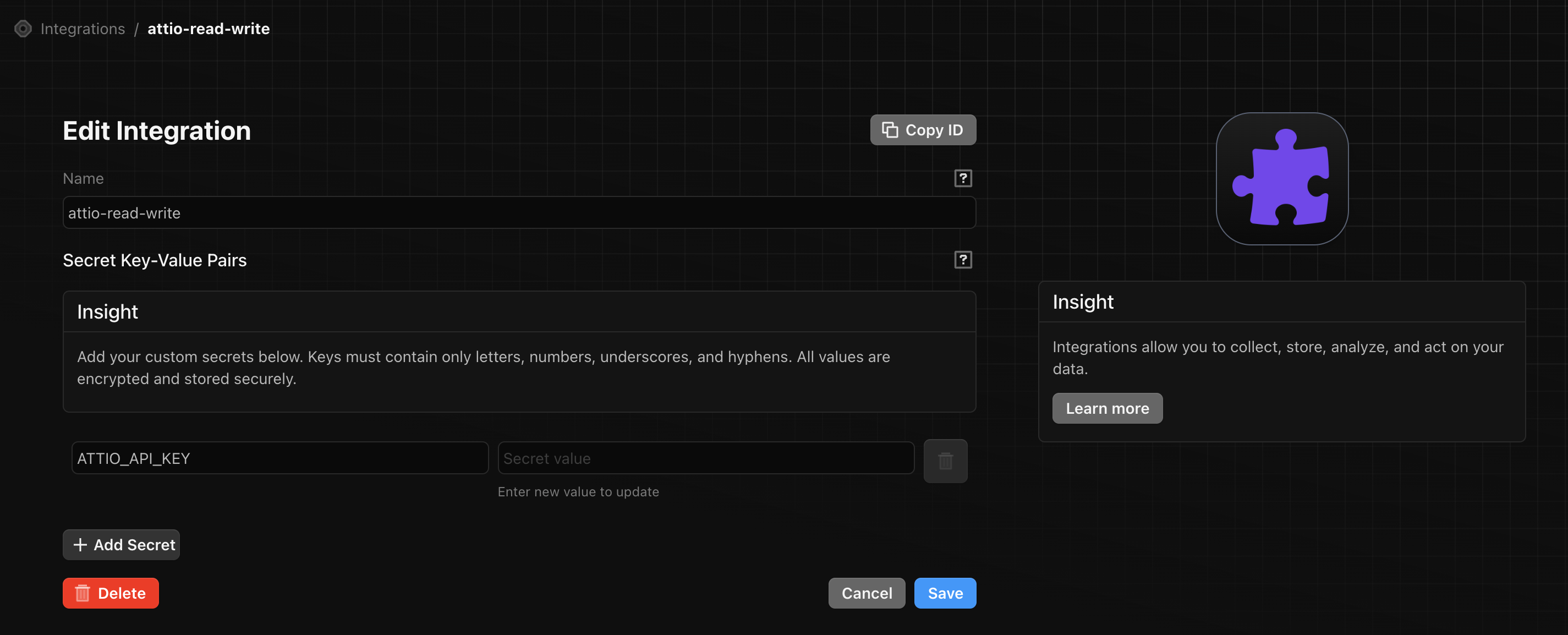
- We use Definite’s Custom Integration feature to securely store the Attio API key and access it with Python (no copy-paste or hardcoded secrets!)
- We patch each record using Attio’s
PATCH /companies/records/:idendpoint
Here’s what the custom integration configuration looks like in Definite.
Here’s the script to sync the data to a CRM (in this case, Attio). We left the emojis in the comments to make it very clear that this code is brought to you by the vibes.
import os
import pandas as pd
import requests
import duckdb
from definite_sdk.client import DefiniteClient
# 🔐 Initialize Definite client and Duck Lake connection
client = DefiniteClient(api_key=os.environ["DEFINITE_API_KEY"], api_url="https://api.definite.app")
conn = duckdb.connect()
conn.execute(client.attach_ducklake())
# 🔍 Load the scores from Duck Lake
query = "SELECT record_id, similarity_score FROM lake.attio.companies_scores"
df_scores = conn.execute(query).fetchdf()
# 🔑 Retrieve Attio API key from integration store
integration_store = client.get_integration_store()
attio_integration = integration_store.get_integration('attio-read-write')
ATTIO_API_KEY = attio_integration.get('secrets').get('ATTIO_API_KEY')
# 🛠️ Function to update score for each company
def update_score(record_id: str, score: int):
endpoint = f"https://api.attio.com/v2/objects/companies/records/{record_id}"
headers = {
"Authorization": f"Bearer {ATTIO_API_KEY}",
"Content-Type": "application/json"
}
payload = {
"data": {
"values": {
"adaa1dcd-3221-4c8c-9e0f-80c40ab82c05": str(score) # Replace with your actual field ID
}
}
}
response = requests.patch(endpoint, headers=headers, json=payload)
response.raise_for_status()
return response.json()
# 🔁 Loop through scores and update Attio
for row in df_scores.to_dict(orient='records'):
record_id = row['record_id']
score = row['similarity_score']
print(f"Updating {record_id} with score {score}")
try:
update_score(record_id, score)
except Exception as e:
print(f"Failed to update {record_id}: {e}")
Now we’ve completed the full loop:
- Pull data from Attio
- Analyze and score it
- Push it back to Attio
The best part: it’s all in one secure easy to manage platform!
Want to go further? You could:
- Swap in OpenAI or Claude to classify each description
- Pull in data from Apollo or Clearbit to enrich company details
- Use this score to trigger automations inside your CRM
- Send conversions to adverstising platforms like Google and Meta
Try it out for yourself, or you could skip all that and have our data team-as-a-service set it all up for you! Contact us to get started.